

Spring:IOC之基于注解管理
注解只是一个标记,作用是框架检测到注解标记的位置,然后针对这个位置按照注解标记的功能来执行具体操作。
本质上:所有一切的操作都是Java代码来完成的,XML和注解只是告诉框架中的Java代码如何执行。
在标识组件时常用的注解有:
@Component:将类标识为普通组件
@Controller:将类标识为控制层组件
@Service:将类标识为业务层组件
@Repository:将类标识为持久层组件
注意,后三个注解都由@Component注解拓展而来,对于Spring使用IOC容器管理这些组件来说没有区别,但出于代码可读性还是要严谨标记。
创建组件与扫描注解要实现基于注解来管理bean,要先创建组件、再扫描组件,
通过注解+扫描,就可以将扫描的包下加上注解的类作为组件作为管理(其实就是在IOC容器内有了加上注解的这个类所对应的bean对象)
以下面这个例子为例 :
创建组件创建控制层组件
123@Controllerpublic class UserController {}
创建接口UserService
注意 : 标记注解就是把加上注解的类在IOC ...

Spring:IOC之基于XML管理
基本内容spring框架的三大特性 : IOC \ AOP \ 声明式事务
IOC ** : 首先,IOC是个容器,可以帮我们管理对象的整个声明周期。代码实现IOC之后,可以用spring来管理对象,其管理的对象叫做组件,也叫做bean**。spring管理bean有两种形式 :
基于xml管理bean
基于注解管理bean
这里讲的主要是基于xml管理bean,主要内容包括 :
xml配置bean
xml获取bean
xml注入依赖
为特殊类型赋值(类类型、数据类型、集合类型等)
bean的作用域
bean的生命周期
FactoryBean
基于xml的自动装配
配置bean在一个maven module中,当有了一个类之后(比如helloworld),可以通过在对应目录的resources中右击Xml configuration -spring config来创建一个xml文件,并在其中添加以下内容 :
12345678910<!--HelloWorld是一个类。配置HelloWorld所对应的bean,即将HelloWorld的对象交给Spring的IOC容器管理通 ...

MySQL索引
索引的出现其实就是为了提高数据查询的效率。
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引和数据就是位于存储引擎层中。
就像书的目录一样,对于数据库的表而言,索引其实就是它的“目录”。
索引常见的模型可以用于提高读写效率的数据结构很多,下面介绍三种常见数据结构,分别是:
哈希表
有序数组
搜索树(包含B+树)
哈希表哈希表是一种以键 - 值(key-value)存储数据的结构,用key找value,时间复杂度为O(1)。
如何做到用key找value ? 通过哈希算法 :
把值放在数组里,用一个哈希算法把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。这样,通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
但是哈希算法有哈希冲突的问题 : 即不同的key通过哈希算法,算出来的值可能会一样,即假设有一种维护身份证和姓名的表,要通过身份证(ID)查看姓名(NAME)。而ID_1和ID_2通过哈希算法算出来的值都是N。。解决办法 :链地址法。
链地址法就是将上面 ...

MySQL日志系统
前一篇文章通过一条查询语句,大概了解了MySQL的基础架构。
本篇文章通过一条更新语句,来大概了解MySQL的日志系统。
1234//建表mysql> create table T(ID int primary key, c int);//更新ID为2的行的C列的值mysql> update T set c=c+1 where ID=2;
首先要知道的是,查询语句那一套流程,更新语句也会先走一遍。(连接器-分析器-优化器-执行器)
与查询的不同点在于 ,更新流程还涉及两个重要的日志模块:
redo log(重做日志):存储引擎层,让MySQL拥有崩溃恢复能力。
binlog (归档日志):server层,同步数据保证数据一致性。
redo log下面说的都是存储引擎层的事儿。
Innodb 基于磁盘存储,同时按 页 的方式来管理记录。如果每次查询或修改都要按页和磁盘进行 IO 交互会严重影响数据库的性能,因此引入了内存缓存,叫做 Buffer Pool
有了内存缓存,在对数据进行查询时,先查缓存,如果数据存在直接返回,如果不存在则去磁盘读取并将读取到的页放到缓存池中, ...

chatGPT教程
前言这是一篇chatGPT注册教程。
ChatGPT(全名:Chat Generative Pre-trained Transformer),通过名字可以看出来是用来transformer模型,其中的精髓是attention机制。attention机制是现代神经网络中的重要模型。有感兴趣的可以去B站看看 李沐老师的课。
言归正传,以下是chatGPT官网:
https://chat.openai.com/
打不开上述网址的请先阅读我的博客《clash使用教程》
如果能打开YouTube却不能打开https://chat.openai.com/ ,参考附录。
其实对于注册chatGPT,除了科学上网的问题,其他麻烦就只剩下国外手机号的验证码接收了。
因此在干一切事情之前,先到 https://sms-activate.org/cn 注册并登录,然后放着就行。(这个网址不需要翻墙,作用是后面用来接受验证码的)
注册看到以下页面,点击sign up
然后就是要求输入邮箱,这里正常输入即可。
笔者在注册时第一次使用了foxmail邮箱,不成功。后换成学校邮箱就成功了,不知道是网 ...
clash教程
仅供个人学习使用,请勿传播。
下载clash for windows,https://github.com/Fndroid/clash_for_windows_pkg/releases,选择你要的版本。
这里笔者选择的是 Clash.for.Windows-0.20.21-win.7z ,点击下载。
此网址是挂载在GitHub上的,如果打不开,可以更换代理或者等一会儿啥的,这里不多说。
安装在你想安装的目录下解压刚刚下好的压缩包。并双击Clash for Windows.exe。不出意外的话就会弹出以下页面了。
如果没有订阅的,先看下一个栏目:订阅
订阅这里订阅的目的是给clash使用的。
有很多机场可以选择,我选择的是 魔戒.net , 我的邀请码 : J5aM0QZt 。
进入注册并登录 ,点击左侧购买订阅,可以选择你想要的套餐。推荐先买130G的体验一下。
订阅完之后重新进入魔戒,点击左侧仪表盘,就可以看到自己的订阅了。
使用订阅完成后,点击左侧使用文档,出现《clash for Windows推荐》,点击进入,有 快速导入功能,可以自动配置Clash ...
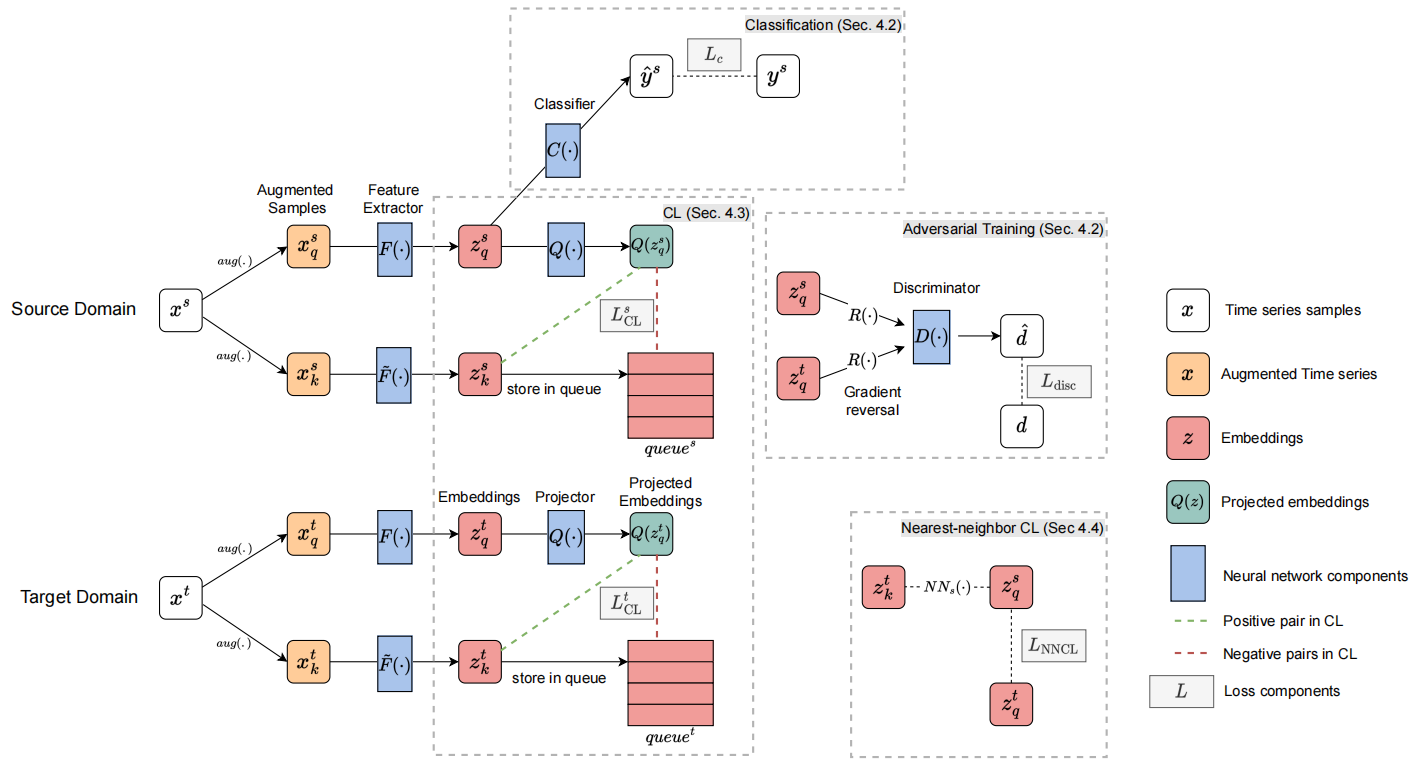
(CLUDA)CONTRASTIVE LEARNING FOR UNSUPERVISED DOMAIN ADAPTATION OF TIME SERIES
[Title]CONTRASTIVE LEARNING FOR UNSUPERVISED DOMAIN ADAPTATION OF TIME SERIES摘要
**Unsupervised domain adaptation (UDA)**: aims at learning a machine learning model using a labeled source domain that performs well on a similar yet different, unlabeled target domain.
CLUDA(本文提出): a novel framework for UDA of time series data。 包含以下三个特色
a contrastive learning framework : learn contextual representations in multivariate time series, so that these preserve label information for the prediction task.
a ...

Java关于接口
本篇文章的主要内容关于Java的接口。
在《Java核心技术卷》中,这部分的内容稍显混乱,笔者第一次阅读时感觉不知所云,想了半天应该怎么写这篇文章。
为了条例更加清晰,这里从以下几个方面来阐述接口 :
接口基本概念
接口示例
接口的应用场景(与抽象类的差别)
接口基本概念接口的基本使用使用接口,要先声明,再实现。
声明接口
123456//声明一个Comparable接口,但没有实现public interface Comparable<T>{ //接口中的方法自动声明为public int compareTo(T other) ; // parameter has type T}
实现接口
实现接口通常有两个步骤 :
将类声明为实现给定的接口(使用关键字 implements:)
1class Employee implements Comparable
对接口中的所有方法进行定义。
123456//注意 ,实现接口的时候要声明public (和声明接口不同)public int compareTo(Object otherObje ...

MySQL基础架构
1select * from T where ID=10;
在MySQL中,上面这句话是最简单不过的查询语句。那么这条语句在MySQL内部是如何执行的?
这个问题,可以囊括MySQL的基础架构。
MySQL基础架构MySQL 可以分为 Server 层和存储引擎层两部分。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB。不同的存储引擎共用一个 Server 层,也就是从连接器到执行器的部分。
下面通过查询语句的作用,依次谈谈架构中Server的各层的基本功能。
主要内容有 :
连接器 :关于长连接问题
查询缓存 : 利大于弊,MySQL8.0以后就被废弃了
分析器 : 词法分析、语法分析
优化器 : 尽可能扫描少的数据库行纪录
执行器 :执行顺序举例
连接器连接器负责跟客户 ...
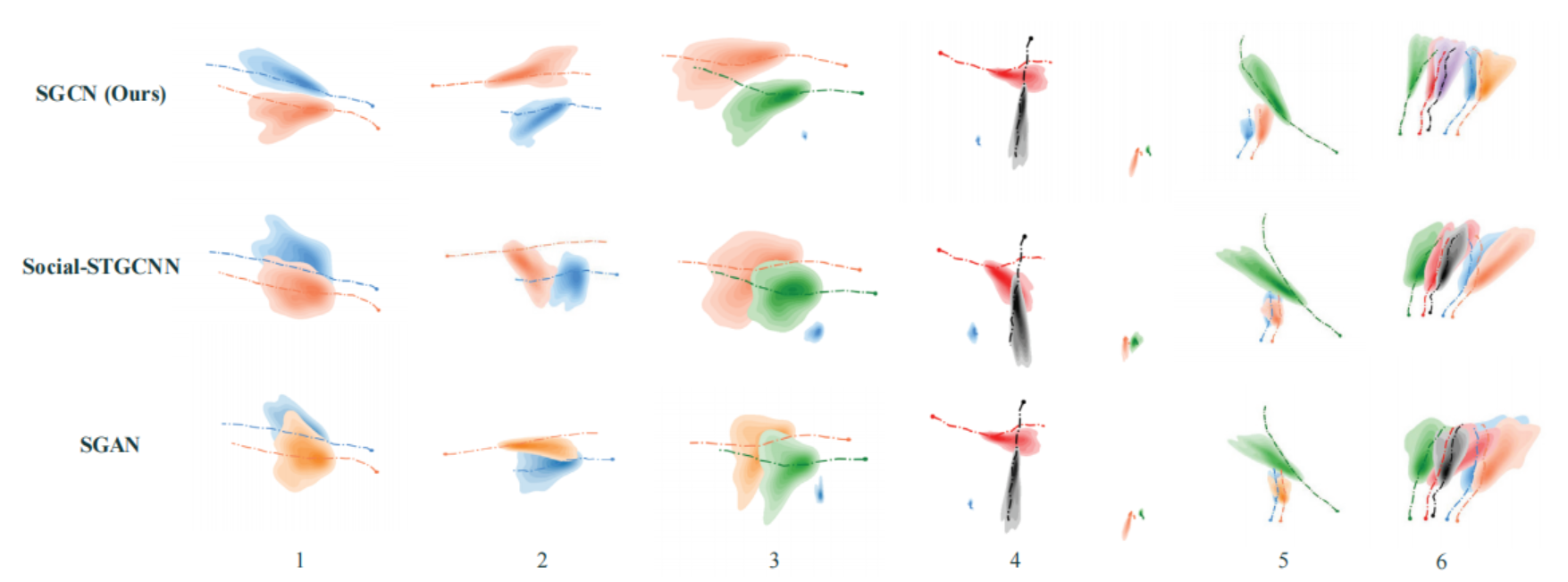
轨迹预测之实验设置
数据集对于行人轨迹预测,常用的数据集为ETH [1]和UCY[2] 。这两个数据集是包含了大量的社会交互,这两个数据集中加起来共有1536名行人,上千条真实轨迹,包含行人绕开障碍物、单个行人与人群的相向而行、路口行人转弯等多种真实场景。是行人轨迹预测常用的基准数据集。其中,又分别包含了5个人群数据集。
EHT : 包含 ETH-univ, ETH-hotel
UCY : 包含 UCY-zara01, UCY-zara02 and UCY-univ.
这两个数据集以每秒2.5帧的速度标记真实位置,在实验中采用观察过去8帧(3.2秒)来预测未来12帧(4.8秒)的形式进行训练与测试。
[1]S. Pellegrini, A. Ess, K. Schindler, and L. J. Van Gool. You’ll never walk alone: Modeling social behavior for multi-target tracking. In ICCV, volume 9, pages 261–268, 2009.
[2] A. Lerner, Y. Chrysant ...