
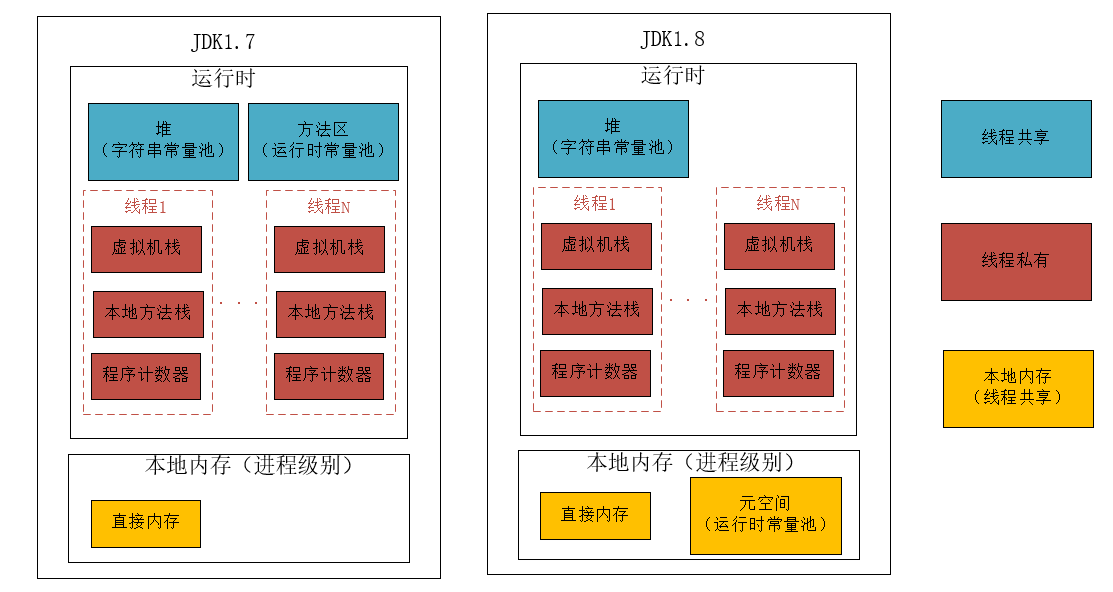
JVM内存区域
JVM内存区域在Java中,内存区域分为静态内存区域和运行时内存区域。
静态内存区域:是在程序编译时就已经分配好的内存区域,用于存储程序中的静态变量和常量。静态区在程序运行期间一直存在,直到程序结束才会被释放。
包括以下两个部分:
静态变量存储区域(Static Variable Storage Area): 这是用于存储静态变量的区域。静态变量在类加载时被分配,它们的值在整个程序运行期间保持不变,可以通过类名直接访问。
常量存储区域(Constant Storage Area): 常量存储区域用于存储编译时的常量数据,如字符串常量、数值常量等。这些常量值在编译阶段就确定,不会发生变化。
运行时内存区域:运行时数据区域是在程序运行时动态分配和管理的,用于存储对象实例、方法调用栈等与程序运行相关的数据。
主要包括以下区域:
堆(Heap):用于存储对象实例和数组。堆中的数据是在运行时动态分配和释放的,它是程序运行期间最主要的内存区域。
虚拟机栈(Stack):简称栈,用于存储方法调用的局部变量、方法参数、返回值和操作数栈。栈中的数据在方法的调用和返回过程中被分配和释放。
方法区 ...

Java代理机制
Java代理机制Java代理分为静态代理与动态代理。
Java提供了两种主要类型的代理:静态代理和动态代理。动态代理是在运行时生成代理对象,通常基于接口,而静态代理是在编译时手动编写代理类。
静态代理就不说了,可以去本站的文章 Spring:AOP简介查看。
从JVM角度来说 :
静态代理是在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。
动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
就 Java 来说,动态代理的实现方式有很多种,比如 JDK动态代理 、 CGLIB动态代理等。
由于miniSpring中使用JDK动态代理实现,这里详细介绍JDK动态代理 .
JDK动态代理在 Java 动态代理机制中 InvocationHandler 接口和 Proxy 类是核心。
以计算器为例,这样一个计算机接口 :
12345public interface Calculator { int add(int a, int b); int subtract(int a, int b);}
其实现为 :
123456 ...

miniSpring开发(8)-实现Servlet任务分派
通过单一的Servlet拦截请求分派任务这里我们的目标是通过一个 Controller 来拦截用户请求,找到相应的处理类进行逻辑处理,然后将处理的结果发送给客户端。
通过单一的Servlet拦截请求并分派任务,通常被称为前端控制器模式,也就是在一个Servlet中集中处理所有的请求,并根据请求的内容将任务分发给相应的处理逻辑。
创建前端控制器Servlet: 首先,你需要创建一个Servlet,该Servlet将作为前端控制器,拦截所有的请求并进行任务分派。在下面的配置文件中,这个Servlet的类是 com.minis.web.DispatcherServlet。
配置Servlet映射: 在下面配置文件中,有 <servlet> 和 <servlet-mapping> 部分。<servlet> 部分定义了前端控制器Servlet的配置,而 <servlet-mapping> 部分将请求路径映射到该前端控制器Servlet。
在下面的配置文件中,前端控制器Servlet的名称是 “minisMVC”,它会拦截根路径 “/“ ...
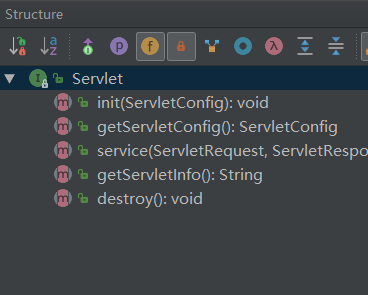
Servlet&Tomcat概览
ServletWhat?Servlet是什么servlet就是一个Java接口,interface! 打开idea,ctrl + shift + n,搜索servlet,就可以看到是一个只有5个方法的interface!
所以servlet的作用,就是接口的作用:规范。
servlet接口定义的是一套处理网络请求的规范,所有实现servlet的类,都需要实现它那五个方法,其中最主要的是两个生命周期方法 init()和destroy(),还有一个处理请求的service(),也就是说,所有实现servlet接口的类,或者说,所有想要处理网络请求的类,都需要回答这三个问题:
你初始化时要做什么
你销毁时要做什么
你接受到请求时要做什么
但是servlet不会直接和[客户端]打交道!需要通过servlet容器,比如我们最常用的tomcat,才能接收到数据。
Why?为什么需要servlet这个问题来举例回答 :
假设你正在开发一个简单的用户注册系统,用户在网页上填写注册信息,包括用户名、密码和电子邮件。你需要将用户提交的信息保存到数据库,并显示一个“注册成功”或“注册失败”页面。
不 ...

miniSpring开发(7)-IoC小结
在使用 IoC 容器时,我们需要先配置容器,包括注册需要管理的对象、配置对象之间的依赖关系以及对象的生命周期等。
然后,IoC 容器会根据这些配置来动态地创建对象,并把它们注入到需要它们的位置上。
当我们使用 IoC 容器时,需要将对象的配置信息告诉 IoC 容器,这个过程叫做依赖注入(DI),而 IoC 容器就是实现依赖注入的工具。
因此,理解 IoC 容器就是理解它是如何管理对象,如何实现 DI 的过程。
以下几个大点,则是在实现方案时的流程与难点。
从XML读取Bean配置首先是要读取xml,这部分内容其实就是 ClassPathXmlApplicationContext类的构造函数。
12//1.加载 XML 配置文件Resource res = new ClassPathXmlResource(fileName);
在 ClassPathXmlResource中,使用了SAXReader插件,可以更好的读取xml结构的文档。
123456789101112public ClassPathXmlResource(String fileName) { SAXRe ...
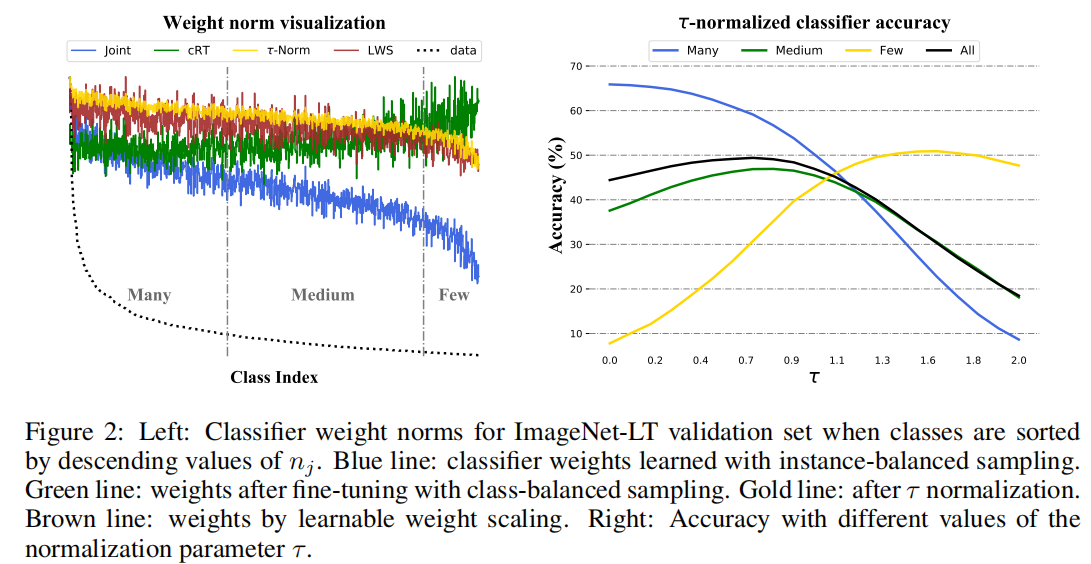
(DRC)Decoupling representation and classifier for long-tailed recognition
标题Decoupling representation and classifier for long-tailed recognition [ICLR 2020]
摘要
现有数据不平衡的处理:Existing solutions usually involve class-balancing strategies, e.g. by loss re-weighting, data re-sampling, or transfer learning from head- to tail-classes, but most of them adhere to the scheme of jointly learning representations and classififiers.
本文 : In this work, we decouple the learning procedure into representation learning and classifification, and systematically explore how different balanc ...
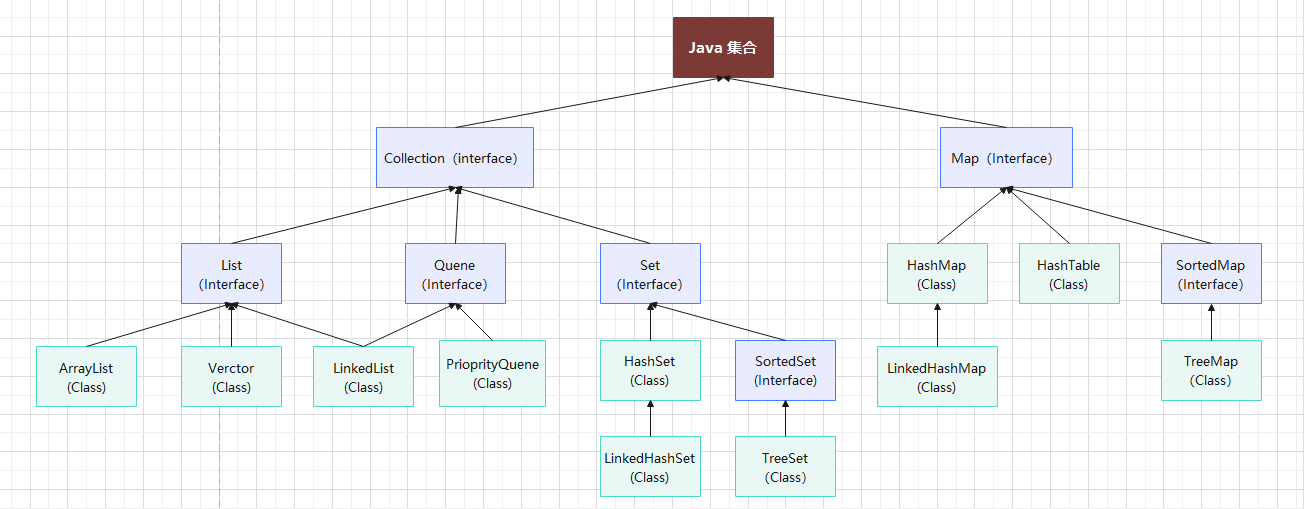
Java集合(容器)
Java集合Java集合又成容器,主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
Collection 和 Map都是接口。而对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
两大接口的实现层级如下图 :
简要概括List、Set 和 Queue、map的区别?
List :(对付顺序的好帮手): 存储的元素是有序的、可重复的,可通过索引访问。
Set(注重独一无二的性质): 存储的元素不可重复的,不能通过索引访问,仅关注元素存在与否。
Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。通常遵循先进先出(FIFO)原则。
Map(用 key 来搜索的专家): 使用键值对(key-value)存储,键是唯一的,但值可以重复。
Collection1. Set
TreeSet:基于红黑树(自平衡的排序二叉树)实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,Has ...
miniSpring开发(6)-支持注解
注解管理Bean
这部分内容来自我的博客文章 《Spring:IOC之基于注解管理》
注解只是一个标记,作用是框架检测到注解标记的位置,然后针对这个位置按照注解标记的功能来执行具体操作。
要实现基于注解来管理bean,要先创建组件、再扫描组件,
通过注解+扫描,就可以将扫描的包下加上注解的类作为组件作为管理(其实就是在IOC容器内有了加上注解的这个类所对应的bean对象)
以下面这个例子为例 :
创建组件创建控制层组件
123@Controllerpublic class UserController {}
扫描组件扫描组件在配置文件中进行扫描,目的在于让Spring知道哪些类加了什么注解。
使用的标签是<context:component-scan> ,扫描的包通过 base-package字段指定。
分为三种情况 : 最基本的扫描方式、指定要排除的方式、指定要扫描的方式
最基本的扫描
123XML<context:component-scan base-package="com.atguigu"></c ...

Java反射机制
Java反射Java 反射是一种强大的机制,允许在运行时检查、访问和操作类、对象、方法、字段等。它使得程序可以在不事先知道类的具体信息的情况下,动态地操作类和对象。Java 反射的主要功能包括:
获取类的信息:通过反射可以获取类的名称、包名、父类、接口、字段、方法等的信息。
创建对象:使用反射可以在运行时动态地创建类的实例,即使类名在编译时不是固定的。
访问字段和方法:反射允许访问对象的字段值和调用对象的方法,包括私有字段和方法。
调用构造函数:通过反射可以实例化类的对象并调用其构造函数,可以是无参构造函数或有参构造函数。
动态代理:反射可以用于创建动态代理对象,用于代理和拦截方法调用,实现 AOP(面向切面编程)等功能。
获取注解信息:反射可以获取类、方法、字段等上的注解信息,从而实现更灵活的配置和编程。
动态加载类:反射可以通过类加载器在运行时动态加载类,这对于插件化、模块化等场景非常有用。
修改字段值:反射可以修改类的字段值,包括私有字段。
操作数组:通过反射可以操作数组,包括创建数组对象、获取元素值、修改元素值等。
动态修改类的结构:反射允许在运行时动态地修改类的结构,例如增 ...
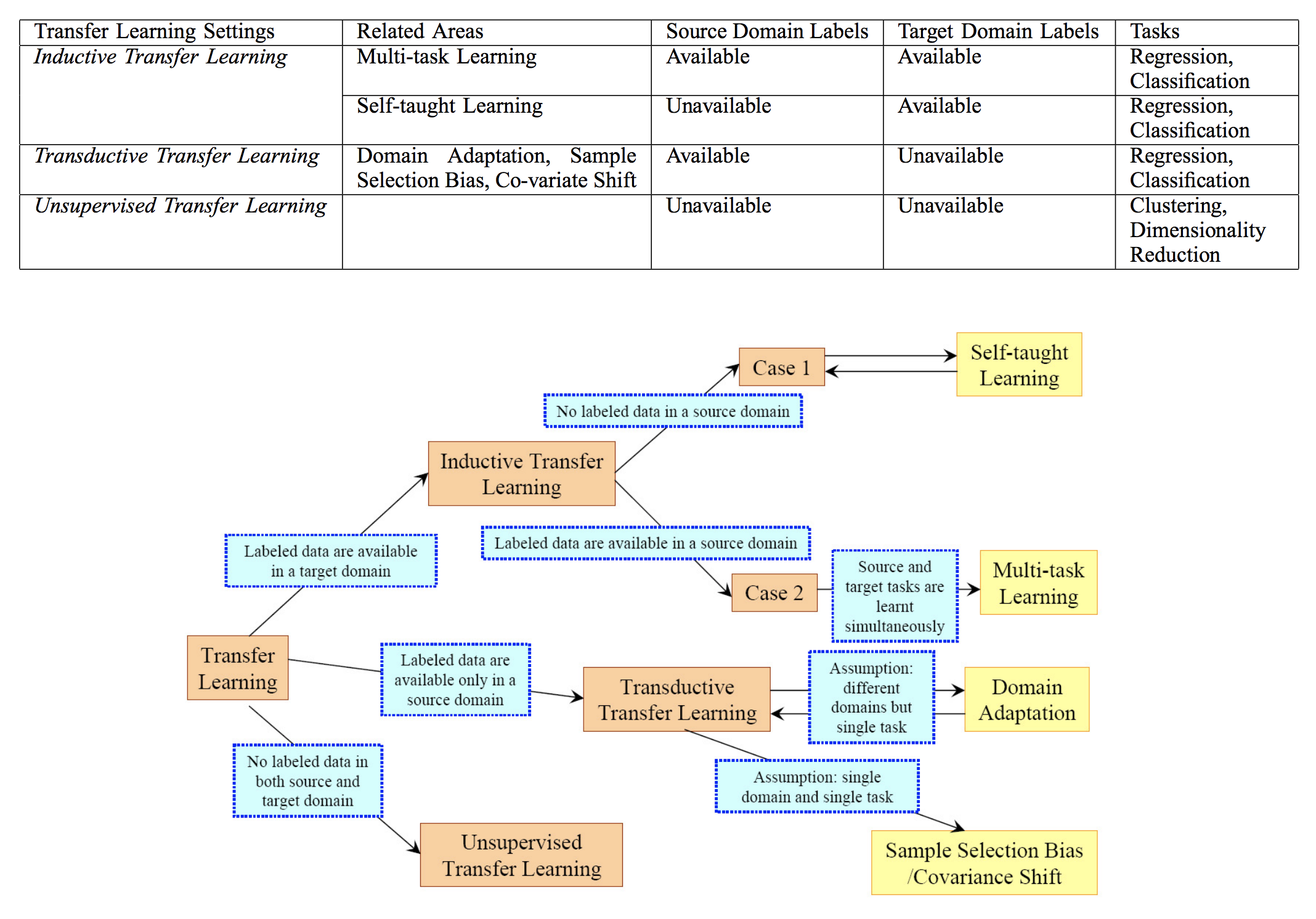
迁移学习概述
简介
Q:请为我简单描述一下迁移学习
chatGPT :
迁移学习是一种机器学习方法,它通过将在一个领域中学到的知识和经验应用于另一个相关领域或任务中。通常情况下,迁移学习的目标是通过利用源领域(称为预训练领域)的数据和模型来改善目标领域(称为目标领域)的学习性能。
在传统机器学习中,每个任务都需要独立地进行训练和学习,而迁移学习则通过共享模型的参数或特征表示来实现跨任务的知识传递。常见的迁移学习方法包括以下几种:
特征提取:在这种方法中,预训练模型在源领域上进行训练,然后将其底层网络作为特征提取器,从源领域的数据中提取出高层次的特征表示。这些特征表示可以用于目标领域的任务。
微调:微调是指在预训练模型的基础上,使用目标领域的数据对模型进行额外的训练。在微调过程中,底层网络的权重会被冻结或者以较小的学习率进行更新,而高层网络的权重则可以更自由地进行调整。
领域自适应:当源领域和目标领域的数据分布不同的时候,领域自适应方法可以通过对源领域和目标领域之间的差异进行建模,来减少分布差异对目标任务性能的影响。
迁移学习的主要优势在于它可以利用已有的数据和知识,从而减少对目标领域的数 ...