PDFBox简介
官网 : https://pdfbox.apache.org/
PDFBox是一个开源的Java库,用于在Java平台上处理PDF文件。它提供了一系列功能,使开发人员能够读取、创建、修改和提取PDF文件的内容。
PDFBox是Apache软件基金会的一个顶级项目,拥有广泛的用户群体和活跃的开发社区。
PDFBox的主要功能包括:
- 读取PDF文件:PDFBox可以将PDF文件解析为文本或其他格式,以便进一步处理和分析PDF内容。
- 创建和修改PDF文件:PDFBox可以生成全新的PDF文件,也可以对现有的PDF文件进行修改,添加文本、图片、链接、表单等内容。
- 提取PDF内容:PDFBox可以从PDF文件中提取文本、图像、链接、元数据等信息,使得开发人员能够轻松地获取和利用这些信息。
- 操作PDF页面:PDFBox允许你对PDF页面进行裁剪、旋转、缩放和合并等操作。
- 处理表单:PDFBox可以填充和提取PDF表单中的数据,使得表单处理变得更加简单。
- 支持加密和签名:PDFBox支持对PDF文件进行加密和数字签名,确保PDF文件的安全性和完整性。
PDFBox是一个功能强大且稳定的库,适用于各种Java应用程序,特别是需要处理PDF文件的场景,如文档处理、报表生成、表单处理、PDF文档解析等。由于它是一个开源项目,因此开发人员可以免费使用、修改和分发PDFBox,并在需要时从活跃的开发社区中获取支持和帮助。
基础使用
依赖
首先下载pdfbox并导入到Java工程中,下载地址 : https://pdfbox.apache.org/download.html
如果使用了MAVEN,可以直接在pom.xml文件中导入依赖 :
1
2
3
4
5
| <dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.24</version>
</dependency>
|
核心服务
新建一个PDFService,并填充以下代码。
各行功能已在代码中进行注释。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| @Service
public class PDFService {
public String extractTextFromPDF(MultipartFile pdfFile) {
try (InputStream inputStream = pdfFile.getInputStream()) {
PDDocument document = PDDocument.load(inputStream);
PDFTextStripper textStripper = new PDFTextStripper();
String pdfText = textStripper.getText(document);
document.close();
return pdfText;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
|
控制器
本项目使用了SwaggerUI,书写一个importPDF的Controller来接收前端PDF文件的导入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Controller
@Api(tags = "标准录入控制器")
@RequestMapping("/api/inputStandard")
@CrossOrigin("http://localhost:9528")
public class InputStandardControl {
@Autowired
private PDFService pdfService;
@PostMapping("/importPDF")
@ResponseBody
@ApiOperation(value = "方法说明:导入PDF",notes = "导入PDF并解析")
public CommonResult importPDF(@RequestPart("file") MultipartFile file){
return CommonResult.success(pdfService.extractTextFromPDF(file));
}
}
|
测试
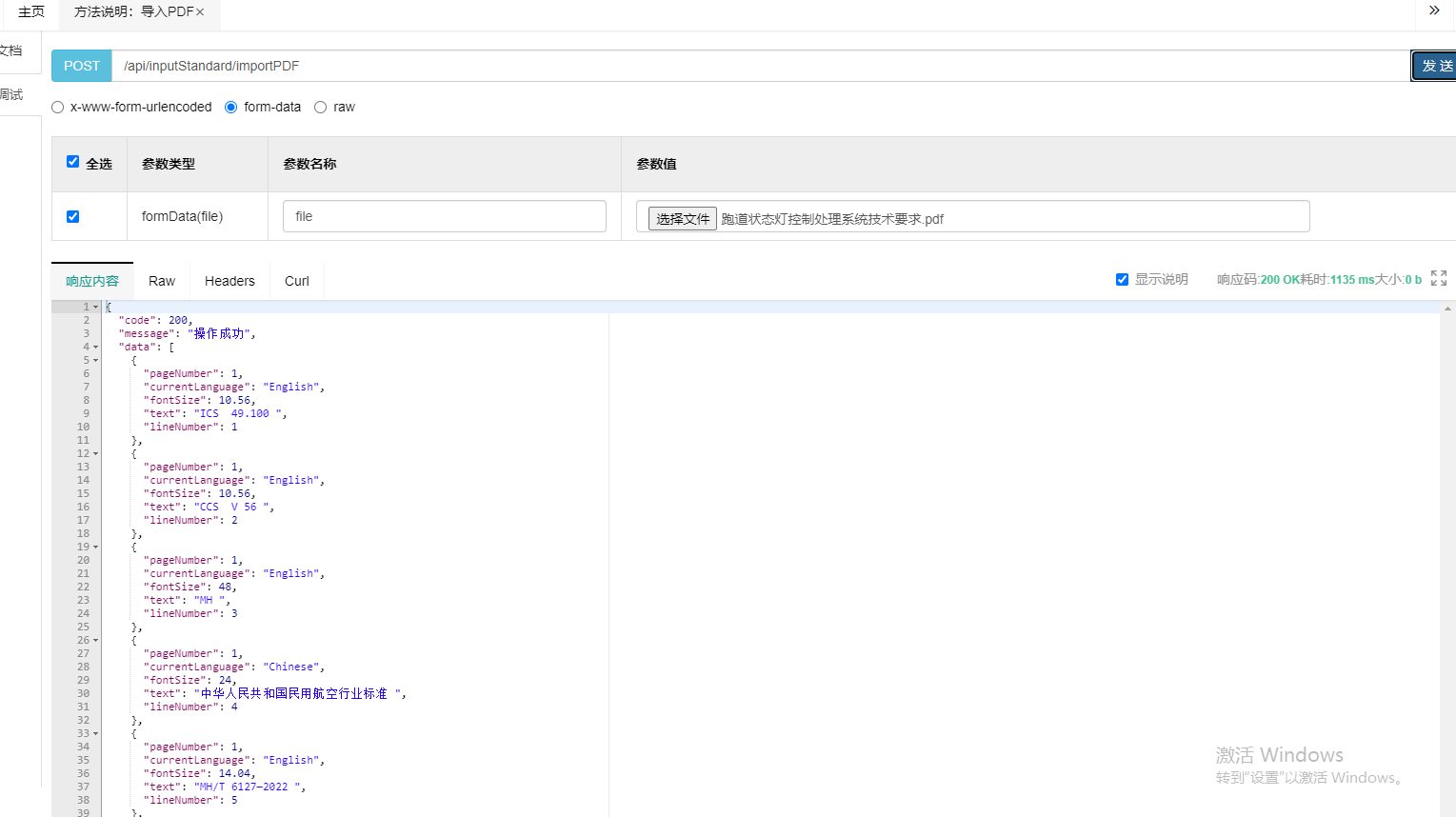
本项目使用了SwaggerUI,启动项目后在SwaggerUI中可以进行测试 :
对于如下pdf


输出结果 :
拓展PDFBox
在上述用法中,可以提取PDF中的文字信息,但未免太过简单,不能获取其他额外的有效信息。
本节主要实现对PDFTextStripper类的拓展,以完成按行提取文字,以及获得该行的字号、行号、语言等信息。
核心类
自定义CustomPDFTextStripper类,实现对 PDFTextStripper的拓展。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| package com.dpf.source.visualTool.util.pdf;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.TextPosition;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class CustomPDFTextStripper extends PDFTextStripper {
public CustomPDFTextStripper() throws IOException {
}
private StringBuilder currentLine = new StringBuilder();
private float currentFontSize = -1;
private PDFont currentFont ;
private String currentLanguage = "unknown";
private int lineNumber = 1;
private int pageNumber = 0;
private List<HashMap<String, Object>> linesInfo = new ArrayList<>();
public List<HashMap<String, Object>> getLinesInfo() {
return linesInfo;
}
@Override
protected void writeString(String text, List<TextPosition> textPositions) throws IOException {
if (!textPositions.isEmpty()) {
currentFontSize = textPositions.get(0).getFontSize();
int chineseCharacterCount = countChineseCharacters(text);
if (chineseCharacterCount > 0) {
currentLanguage = "Chinese";
} else {
currentLanguage = "English";
}
}
currentLine.append(text);
super.writeString(text, textPositions);
}
@Override
protected void writeLineSeparator() throws IOException {
HashMap<String, Object> lineInfo = new HashMap<>();
lineInfo.put("text", currentLine.toString());
lineInfo.put("fontSize", currentFontSize);
lineInfo.put("currentLanguage", currentLanguage);
lineInfo.put("lineNumber", lineNumber);
lineInfo.put("pageNumber", pageNumber);
linesInfo.add(lineInfo);
currentLine.setLength(0);
lineNumber++;
super.writeLineSeparator();
}
@Override
protected void writePageStart() throws IOException {
lineNumber = 1;
pageNumber ++;
super.writePageStart();
}
private int countChineseCharacters(String text) {
int count = 0;
for (char c : text.toCharArray()) {
if (isChineseCharacter(c)) {
count++;
}
}
return count;
}
private boolean isChineseCharacter(char c) {
return (c >= '\u4e00' && c <= '\u9fff');
}
}
|
核心服务
PDFService服务中,根据上述的类定义,引入相应功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
@Service
public class PDFService {
public List<HashMap<String,Object>> extractInfoFromPDFWithLine(MultipartFile pdfFile){
List<String> lines = new ArrayList<>();
List<HashMap<String,Object>> PDFLines = new ArrayList<>();
try (InputStream inputStream = pdfFile.getInputStream()) {
PDDocument document = PDDocument.load(inputStream);
CustomPDFTextStripper textStripper = new CustomPDFTextStripper();
int startPage = 1;
int endPage = Math.min(document.getNumberOfPages(), 5);
textStripper.setStartPage(startPage);
textStripper.setEndPage(endPage);
textStripper.getText(document);
document.close();
return textStripper.getLinesInfo();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
|
控制器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Controller
@Api(tags = "标准录入控制器")
@RequestMapping("/api/inputStandard")
@CrossOrigin("http://localhost:9528")
public class InputStandardControl {
@Autowired
private PDFService pdfService;
@PostMapping("/importPDF")
@ResponseBody
@ApiOperation(value = "方法说明:导入PDF",notes = "导入PDF并解析")
public CommonResult importPDF(@RequestPart("file") MultipartFile file){
return CommonResult.success(pdfService.extractInfoFromPDFWithLine(file));
}
}
|
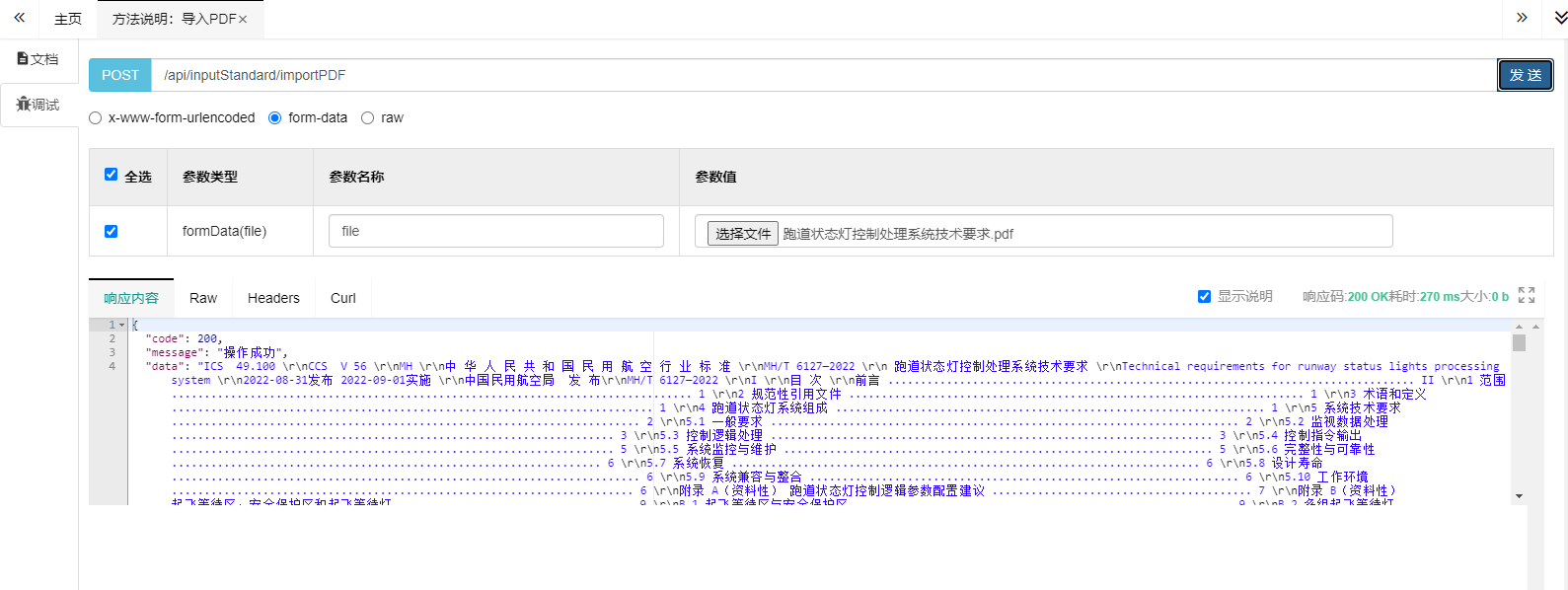
测试
还是前面那个PDF文件从,测试结果如图 :