
Java集合(容器)
Java集合
Java集合又成容器,主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。
Collection 和 Map都是接口。而对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
两大接口的实现层级如下图 :
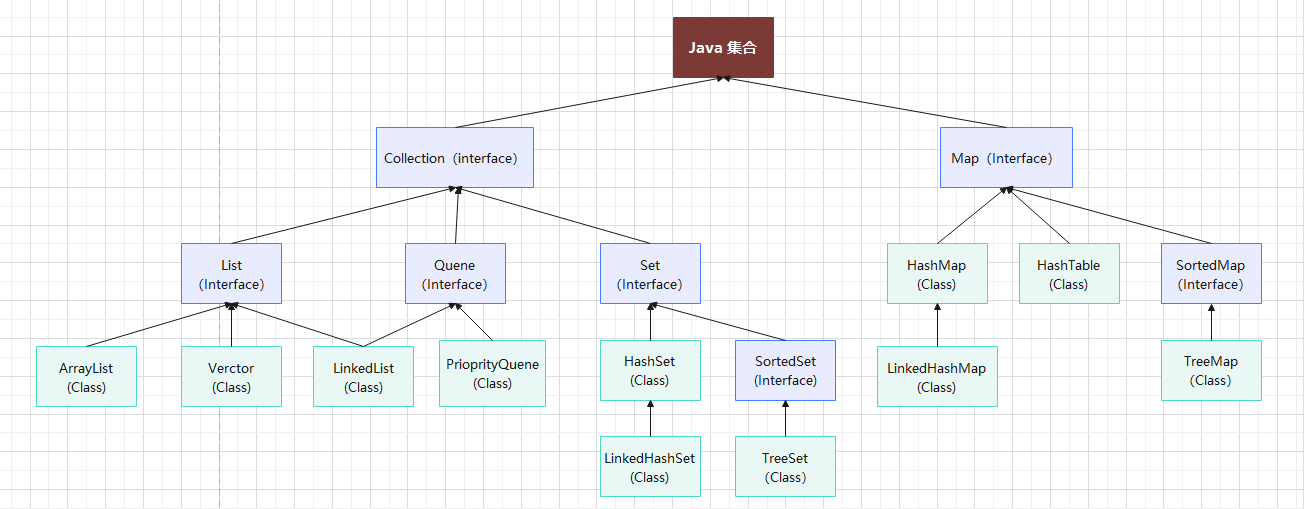
简要概括List、Set 和 Queue、map的区别?
List:(对付顺序的好帮手): 存储的元素是有序的、可重复的,可通过索引访问。Set(注重独一无二的性质): 存储的元素不可重复的,不能通过索引访问,仅关注元素存在与否。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。通常遵循先进先出(FIFO)原则。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,键是唯一的,但值可以重复。
Collection
1. Set
TreeSet:基于红黑树(自平衡的排序二叉树)实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
HashSet:基于哈希表(HashMap)实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- 相同点:
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。 - 不同点:
- 底层数据结构:
HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。 - 应用场景:底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
- 底层数据结构:
- 相同点:
2. List
ArrayList:基于动态数组实现,支持随机访问。相比
Array(静态数组),有以下特点:比
Array(静态数组) 使用起来更加灵活,ArrayList会根据实际存储的元素动态地扩容或缩容,而Array被创建之后就不能改变它的长度了ArrayList支持插入、删除、遍历等常见操作,并且提供了丰富的 API 操作方法,比如add()、remove()等。Array只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。ArrayList允许你使用泛型来确保类型安全,Array则不可以。ArrayList在创建时不需要声明大小,而Array必须要。但
ArrayList中只能存储对象(对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)),Array可以存储对象或者基本类型。下面是二者使用的简单对比:
Array:1
2
3
4
5
6
7
8
9
10
11// 初始化一个 String 类型的数组
String[] stringArr = new String[]{"hello", "world", "!"};
// 修改数组元素的值
stringArr[0] = "goodbye";
System.out.println(Arrays.toString(stringArr));// [goodbye, world, !]
// 删除数组中的元素,需要手动移动后面的元素
for (int i = 0; i < stringArr.length - 1; i++) {
stringArr[i] = stringArr[i + 1];
}
stringArr[stringArr.length - 1] = null;
System.out.println(Arrays.toString(stringArr));// [world, !, null]ArrayList:1
2
3
4
5
6
7
8
9
10
11// 初始化一个 String 类型的 ArrayList
ArrayList<String> stringList = new ArrayList<>(Arrays.asList("hello", "world", "!"));
// 添加元素到 ArrayList 中
stringList.add("goodbye");
System.out.println(stringList);// [hello, world, !, goodbye]
// 修改 ArrayList 中的元素
stringList.set(0, "hi");
System.out.println(stringList);// [hi, world, !, goodbye]
// 删除 ArrayList 中的元素
stringList.remove(0);
System.out.println(stringList); // [world, !, goodbye]
Vector:和 ArrayList 类似,但它是线程安全的。
LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
3. Queue
- LinkedList:可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。其与
Queue的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。 Queue是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。Deque是双端队列,Deque扩展了Queue的接口,在队列的两端均可以插入或删除元素。
Map
- HashMap:
- 特点:使用哈希表实现,具有快速的查找性能。键和值可以为
null。不保证元素的顺序。 - 优点:查找、插入、删除操作的平均时间复杂度为 O(1),性能较好。
- 缺点:不保证元素的有序性,遍历时元素的顺序可能不一致。不是线程安全的。
- 适用场景:适用于需要快速查找和插入操作,且对元素顺序不敏感的情况。不适用于多线程环境。
- 特点:使用哈希表实现,具有快速的查找性能。键和值可以为
- LinkedHashMap:
- 特点:继承自
HashMap,保持元素的插入顺序或访问顺序。比HashMap多维护了一个双向链表。 - 优点:具有
HashMap的快速查找性能,同时保持插入顺序或访问顺序。 - 缺点:相较于
HashMap,额外维护了链表,可能占用更多内存。 - 适用场景:适用于需要保持插入顺序或访问顺序,并且查找性能要求较高的情况。
- 特点:继承自
- TreeMap:
- 特点:使用红黑树实现,保持元素的自然顺序或自定义比较器的顺序。
- 优点:具有有序性,查找、插入、删除操作的时间复杂度为 O(log n)。
- 缺点:性能较
HashMap和LinkedHashMap差,因为涉及红黑树的操作。 - 适用场景:适用于需要保持有序性的情况,对性能要求不是特别高的情况。
- Hashtable:
- 特点:早期的实现类,类似于
HashMap,但线程安全,所有方法都是同步的。 - 优点:线程安全,适用于多线程环境。
- 缺点:同步机制会引入性能开销。键和值都不能为
null。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。 - 适用场景:适用于多线程环境,但性能相较于其他实现类较低,现在不推荐使用。
- 特点:早期的实现类,类似于





