(FEND)A Future Enhanced Distribution-Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
[Title]FEND: A Future Enhanced Distribution-Aware Contrastive Learning Framework for Long-tail Trajectory Prediction(CVPR2023)
摘要
- 困难 : trajectory prediction suffers from data imbalance in the prevalent datasets, and the tailed data is often more complicated and safety-critical.
- 本文目标 : we focus on dealing with the long-tail phenomenon in trajectory prediction.
- 前人不足 : Previous methods dealing with long-tail data did not take into account the variety of motion patterns in the tailed data.
- 本文特色 :
- In this paper, we put forward a future enhanced contrastive learning framework to recognize tail trajectory patterns and form a feature space with separate pattern clusters.
- Furthermore, a distribution aware hyper predictor(分布感知超预测器) is brought up to better utilize the shaped feature space.
- Our method is a model-agnostic framework and can be plugged into many well-known baselines.
长尾问题
来源 : 样本(类别)样本不平衡(class-imbalance)指的是分类任务中不同类别的训练样例数目差别很大的情况,一般地,样本类别比例(Imbalance Ratio)(多数类vs少数类)明显大于1:1(如4:1)就可以归为样本不均衡的问题。现实中,样本不平衡是一种常见的现象,如:金融欺诈交易检测,欺诈交易的订单样本通常是占总交易数量的极少部分,而且对于有些任务而言少数样本更为重要。
举例:在真实的交通场景中,大多数轨迹遵循一定简单的运动规则,而偏离和避免碰撞的情况很少。因此,频繁出现的情况往往简单、容易预测,而尾部情况往往复杂,运动模式多,预测误差大,使得univ数据集更加对安全看重,如图1所示。尽管长尾预测问题具有重要意义,但在文献中很少被讨论。
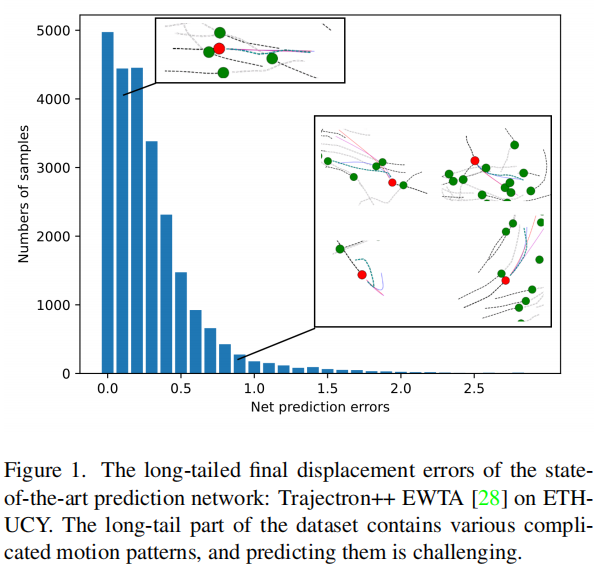
定义:只有少量的类别含有较多样本(head),大部分类别的样本数都很少(tail)
简介
背景 :Despite the high accuracy those prediction methods have achieved, most of them treat the samples in the datasets equally in both training and evaluation phases. But there is a long-tailed phenomenon in prevalent datasets
本文提出:A new framework is developed called FEND: Future ENhanced Distribution-aware contrastive trajectory prediction(未来增强分布感知对比轨迹预测), which is a pattern-based contrastive feature learning framework enhanced by future trajectory information.
贡献:(对应上述方法)
- We propose a future enhanced contrastive feature learning framework for long-tailed trajectory prediction, which can better distinguish tail patterns from head patterns, and the different patterns are represented by different cluster prototypes to enhance the modeling of the tailed data.
- We propose a distribution-aware hyper predictor, aiming at providing separated decoder parameters for trajectory inputs with different patterns.
方法
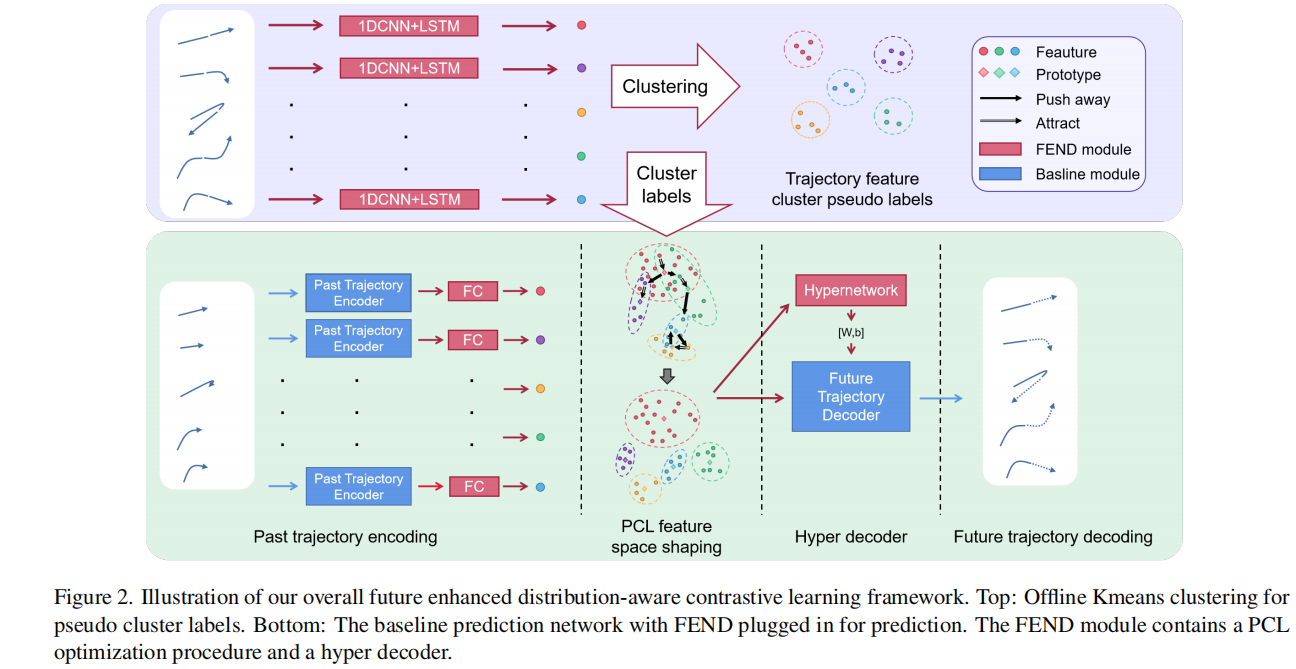
概览
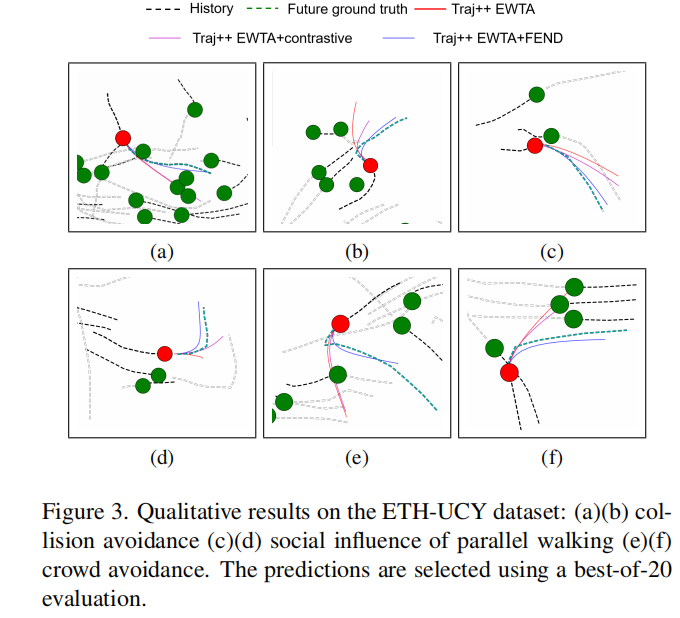
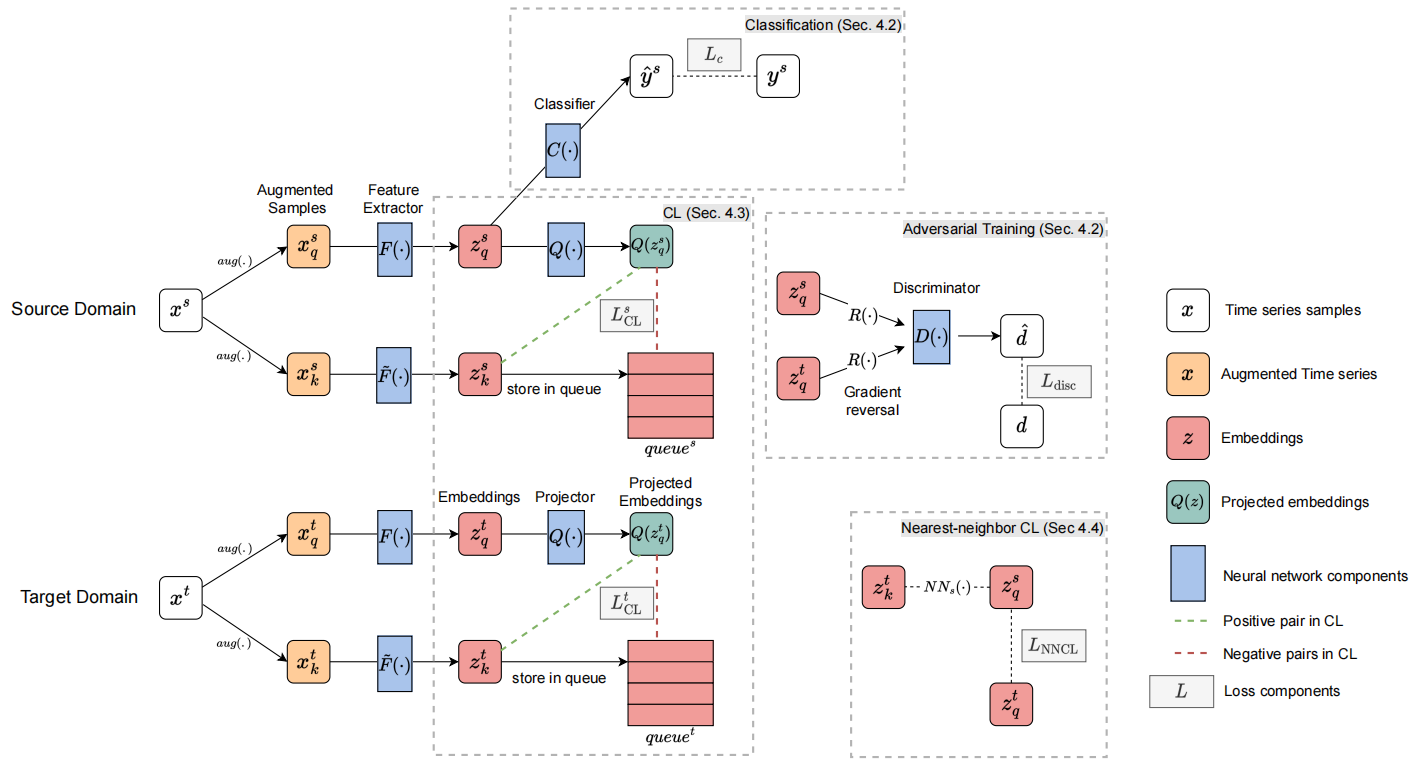
总体框架如上图。
- 首先用轨迹特征提取器对历史轨迹和未来轨迹进行处理,用Kmeanes对提取的特征进行聚类,形成不同的模式聚类。(上半部分左边)
- 聚类后,利用历史和未来信息自发地分离尾部轨迹模式和头部轨迹模式。(上半部分右边)
- 根据Kmeans生成的伪聚类标签(下半部分Past trajectory encoding)对基线预测网络的历史编码特征进行PCL处理。
- 通过执行PCL算法,对轨迹编码器的特征空间分别进行了单独的聚类。
- 然后构造了超解码器,该解码器为不同的轨迹输入生成单独的解码器权重,因此头簇和尾簇中的轨迹被不同地预测。
Future Enhanced Contrastive Learning
此部分在文中分为 Future Enhanced Trajectory Clustering 和 Prototypical Contrastive Learning,前者用来生成对比样本,而后者进行PCL(原型对比学习)流程。
Future Enhanced Trajectory Clustering使用多层次的聚类来执行Kmeans来实现层次结构,就像原始的PCL那样。
Prototypical Contrastive Learning
首先是损失函数 :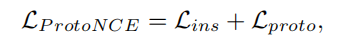
跟PCL所属相同,第一项是实例级的对比项,第二项是实例-原型对比项
而Lins和Lproto又分别如下
Instance-wise term
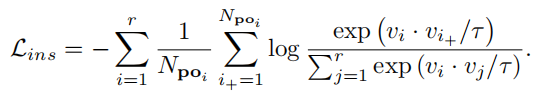
实例级项可以帮助实例更快地聚集在一起,并且算法收敛得更快。
正样本i+为与实例i来自同一簇的实例,批中的其他实例(即属于其他簇),视为负样本。j表示当前批处理数据中的任意样本。r表示批处理的大小。
Instance-prototype term
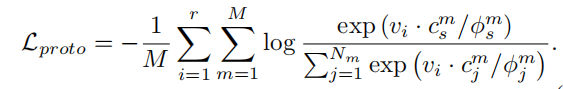
原型项有助于保持局部平滑性和形成具有不同模式的集群。
M为Kmeans聚类层次结构的个数,cms表示i所属的聚类的原型,cmj表示任意聚类j的原型。
该原型是通过取一个集群中所有特征的平均值来计算的。Nm表示层次结构m的集群数。ϕmj表示簇j的密度
Distribution-Aware Hyper Predictor
目标 :头部簇和尾部簇应该被分配不同的解码器
困难 :尾部样本的数据量不足 (根据聚类结果,可以对数据量比较小的簇进行扩容(数据增强)再训练解码器,就解决了尾部数据不足的问题,这里就不用超网了) ,单独训练解码器会导致严重的过拟合。
方法 :使用超网络HyperNetworks。希望在整个数据集上转移公共知识,同时保持单独解码器的建模灵活性。
超网络(Hypernetworks,ICLR2017)表示用于产生较大规模网络参数的小规模网络,在这一过程中,主网络的作用与其他任意神经网络一样,将输入样本映射到对应的目标值,而超网络的作用则是接收一系列包含主网络参数结构信息的值作为输入然后产生主网络某一层的参数。
原文 :D. Ha, A. Dai, and Q. V. Le, ‘HyperNetworks’. arXiv, Dec. 01, 2016. Accessed: Mar. 13, 2023. [Online]. Available: [http://arxiv.org/abs/1609.09106]
普通LSTM trajectory decoder
i、g、f、o分别为输入门、更新门、遗忘门和输出门。
f(t)是遗忘门门控,m(t-1)是历史状态信息,两者相乘代表t时刻允许多少历史信息进入来决定m(t)当前状态
如果遗忘门全关取值0,则历史对当前状态无影响,如果遗忘门全开取值1,则历史信息原封不动的传到t时刻,没有任何信息损失,当然更大可能是取值0到1之间,代表历史信息的部分流入;
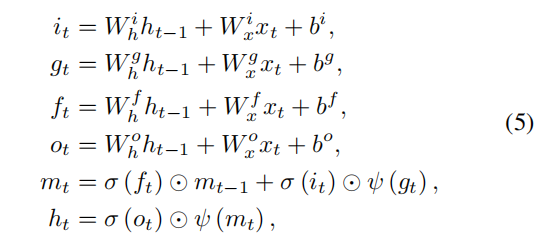
HyperLSTM
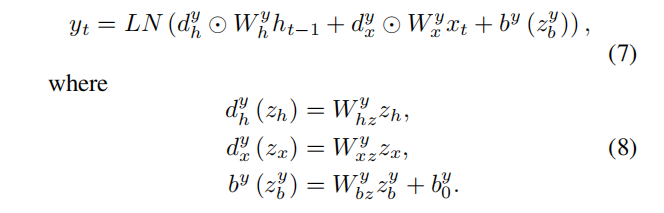
y表示原始LSTM公式等式中{i、g、f、o}四个门中的一个。
⊙表示元素级乘积操作,LN()表示层的归一化,ds和b是来自超网络的权值和偏差调整向量,以改变原始LSTM中的权值和偏差。
ds和b是由超网络的输出z生成的,指从超网络生成的权重和偏差调整向量,用于改变原始LSTM网络的权重和偏差。如在等式中(8),其中Ws和by0为线性全连接层的权值和偏差。
z可以写成如下,例如i与输入特性vi:(其中fH为超网络映射函数)
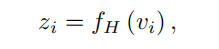
Loss Reweighting
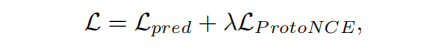
其中Lpred为基线预测网络的损失,λ是PCL损失项的系数。
对于网络已经完美拟合的简单样本,PCL损失几乎不会给网络优化带来更多的好处。
因此,我们使λ在不同的样本中有所不同,它作为一个门来关闭容易的样本上的PCL损失。
我们使用热身训练阶段后网络的预测损失Lpred来表示样本的复杂度,记为L’pred。
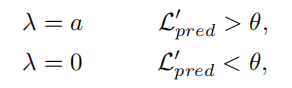
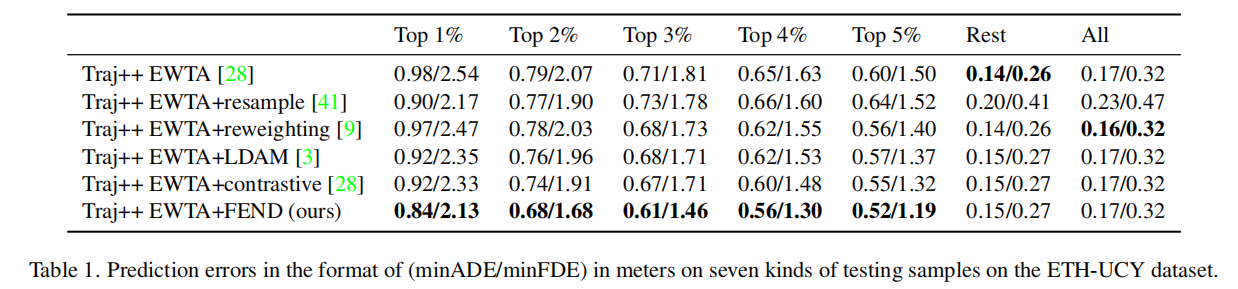
Experiments
为了在长尾数据上证明模型,我们需要对困难样本和那些容易进行评估的样本进行分离。
具体来说,将数据集划分为7种样本:具有挑战性、误差最大的前1%-5%的样本,其余更容易获得的样本,以及数据集中的所有样本。
下表为结果: