Redis简介与数据结构
Redis简介
官网简介 : https://redis.io/docs/about/
- Redis是一个开源在内存中进行数据存储的数据库,Redis 存储的是 KV 键值对数据。
- 被数百万开发人员用作数据库、缓存、流媒体引擎和消息代理。
- Redis的数据结构包括 : strings, hashes, lists, sets, sorted sets with range queries(带范围查询的排列集合), bitmaps(位图), hyperloglogs(超日志), geospatial indexes(地理空间索引), and streams.
- Redis支持 :replication(复制), Lua scripting(Lua脚本), LRU eviction(LRU驱逐), transactions(事务), and different levels of on-disk persistence(不同级别的持久化), and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster(开箱即用的集群方案Redis sentinel 和 redis cluster).
为什么使用Redis?
主要是两个原因 : 高性能 ,高并发
高性能
在MySQL中,用户第一次访问数据库中的数据时,是从磁盘读取,速度较慢。
但redis是在内存中进行数据存储,速度快。
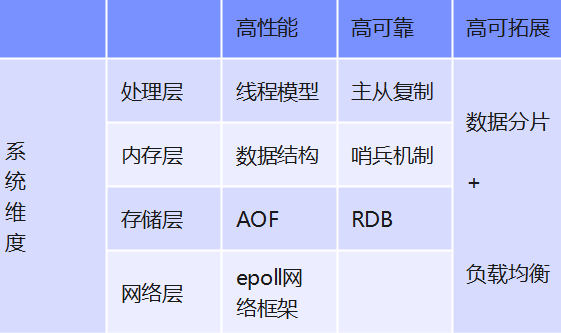
在系统维度的高性能实现 :
- 处理层 :线程模型
- 内存层:数据结构
- 存储层:AOF
- 网络层 : epoll网络框架
高并发
QPS(Query Per Second):服务器每秒可以执行的查询次数;
在MySQL中,QPS:约1w
在单核Redis中:10w+ (使用redis集群更高)
高可靠
在系统维度的高可靠实现 :
- 处理层 :主从复制
- 内存层:哨兵机制
- 存储层:RDB
高可拓展
通过数据分片和负载均衡实现。
Redis应用
- 缓存。例如作为MySQL的缓存。
- 分布式锁。例如Redis的拓展Redisson
- 限流。(Redis + Lua 脚本的方式来实现限流)
- 消息队列。可以,但几乎不会用(Redis 自带的 list 数据结构可以作为一个简单的队列使用。)
- 复杂业务场景。
Redis系统观
以下是redis三大主线
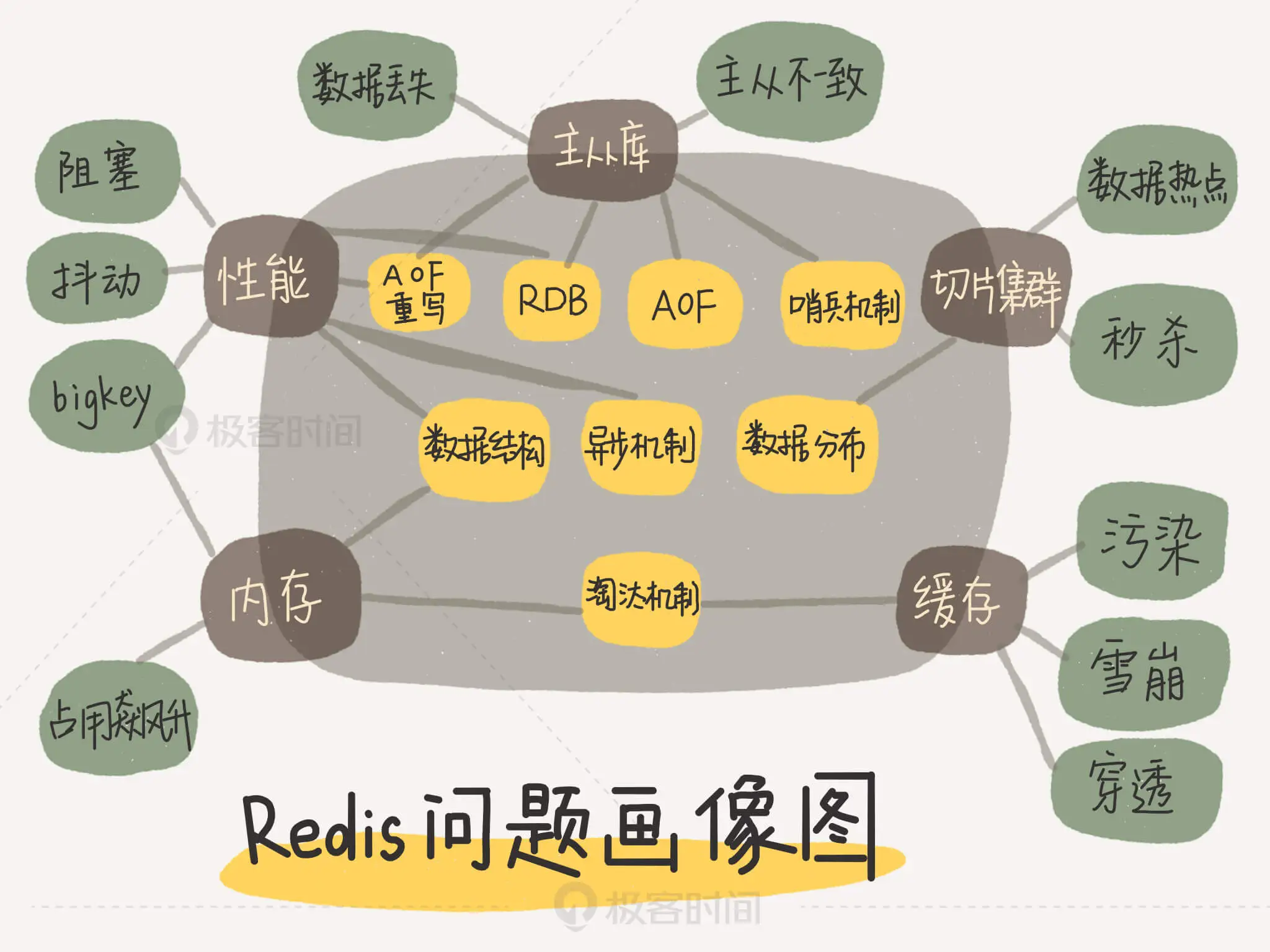
以下是redis 问题-主线-技术点的汇总图。
来自极客时间《Redis核心技术与实战》
Redis这么快,主要归功于三个方面
- Redis 基于内存,内存的访问速度是磁盘的上千倍;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式);
- Redis 内置了多种优化过后的数据结构实现,性能非常高。
因此下面 首先来看看Redis数据结构.
Redis数据结构
Redis常用的数据结构有:
5 种基础数据结构:String(字符串)、List(列表)、Hash(散列)、Set(集合)、Sorted Set(有序集合)。
3 种特殊数据结构:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)
String
底层实现 : 简单动态字符串
应用场景:
- 需要存储常规数据的场景 : 例如缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
- 需要计数的场景 : 用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
- 分布式锁.
List
底层实现 : 双向链表 + 压缩列表
应用场景:
- 信息流展示 :最新文章\动态等
- 消息队列 (但存在不能以消费组形式消费数据等问题)
Hash
底层实现 : 压缩列表 + 哈希表
应用场景 :
- 对象数据存储场景 : 缓存对象、用户信息、商品信息、购物车等。
Set
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
著作权归Guide所有 原文链接:https://javaguide.cn/database/redis/redis-data-structures-01.html#%E4%BB%8B%E7%BB%8D-3
底层实现 : 哈希表 + 整数数组
应用场景 :
- 需要存放的数据不能重复的场景 : 文章点赞、动态点赞等
- 需要获取多个数据源交集、并集和差集的场景 : 共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
- 需要随机获取数据源中的元素的场景 : 抽奖系统、随机点名等场景。
Sort Set
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
著作权归Guide所有 原文链接:https://javaguide.cn/database/redis/redis-data-structures-01.html#%E5%BA%94%E7%94%A8%E5%9C%BA%E6%99%AF-3
底层实现 : 压缩列表 + 跳表
应用场景 :
- 需要随机获取数据源中的元素根据某个权重进行排序的场景 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜 …
- 需要存储的数据有优先级或者重要程度的场景 : 优先级任务队列。