
MySQL索引
索引的出现其实就是为了提高数据查询的效率。
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引和数据就是位于存储引擎层中。
就像书的目录一样,对于数据库的表而言,索引其实就是它的“目录”。
索引常见的模型
可以用于提高读写效率的数据结构很多,下面介绍三种常见数据结构,分别是:
- 哈希表
- 有序数组
- 搜索树(包含B+树)
哈希表
哈希表是一种以键 - 值(key-value)存储数据的结构,用key找value,时间复杂度为O(1)。
如何做到用key找value ? 通过哈希算法 :
把值放在数组里,用一个哈希算法把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。这样,通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
但是哈希算法有哈希冲突的问题 : 即不同的key通过哈希算法,算出来的值可能会一样,即假设有一种维护身份证和姓名的表,要通过身份证(ID)查看姓名(NAME)。而ID_1和ID_2通过哈希算法算出来的值都是N。。解决办法 :链地址法。
链地址法就是将上面ID_1和ID_2对应的NAME_1和NAME_2都放入一个链表。那么要查ID_2对应的value时,根据哈希值N算出来的地址是一个链表,然后再在链表中按顺序遍历,根据key来找value。当然了,如果链表过长,搜索时间就会很长,因此JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树。
哈希表的缺点 :因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了,所以哈希索引做区间查询的速度是很慢的。
哈希表使用场景:只有等值查询的场景。
有序数组
有序数组在等值查询和范围查询场景中的性能就都非常优秀。
如果还是要根据身份证号查姓名,那么有序数据在存储时,会根据ID增序来存储。这时候如果你要查 ID_2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。
同时很显然,这个索引结构支持范围查询。
有序数组的缺点 : 更新数据时太麻烦。
有序数组索适用场景 :静态存储引擎(比如2017 年某个城市的所有人口信息,这类不会再修改的数据。)
搜索树(B+树)
二叉搜索树的特点是:父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值。详细的使用可见https://leetcode.cn/problems/search-in-a-binary-search-tree/ ,时间复杂度是 O(log(N))。
当然为了维持 O(log(N)) 的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是 O(log(N))。
由于索引不止存在内存中,还要写到磁盘上。所以为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么在实际使用中,就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
N 叉搜索树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引擎中了。
B+树是N叉平衡搜索树。
关于B树和B+树,可以看看这篇博客 https://blog.csdn.net/weixin_45271990/article/details/118442958
关于B树与B+树的更多内容,后面再写一篇文章吧 。
InnoDB 的索引模型(B+树)
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。而即使多个存储引擎支持同一种类型的索引,其底层的实现也可能不同。由于 InnoDB 存储引擎在 MySQL 数据库中使用最为广泛,所以下面我就以 InnoDB 为例,分析一下其中的索引模型。
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。每一个索引在 InnoDB 里面对应一棵 B+ 树。
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引。
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
覆盖索引&联合索引
从前面可知,基于普通索引的查询会发生回表,这个过程明显是比较浪费时间的,那么有没有可能经过索引优化,避免回表过程呢?
答案是覆盖索引。
覆盖索引 : 如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 覆盖索引(Covering Index) 。
举例 :
如果执行的语句是 select * from T where k = 3。k不是主键索引,因此逻辑是, 需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。
而如果执行的语句是 select ID from T where k = 3,只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
如何实现 ? 可以通过联合索引的方法。
假设我们只需要查询商品的名称、价格,有什么方式可以避免回表呢?
我们可以建立一个联合索引,即「商品ID、名称、价格」作为一个联合索引。如果索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表。
1 | **联合索引写法** |
最左前缀原则
最左前缀匹配原则指的是,在使用联合索引时,MySQL 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 **>、<**)才会停止匹配。对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
举例 :最左匹配原则,字符串索引的存储方式是:
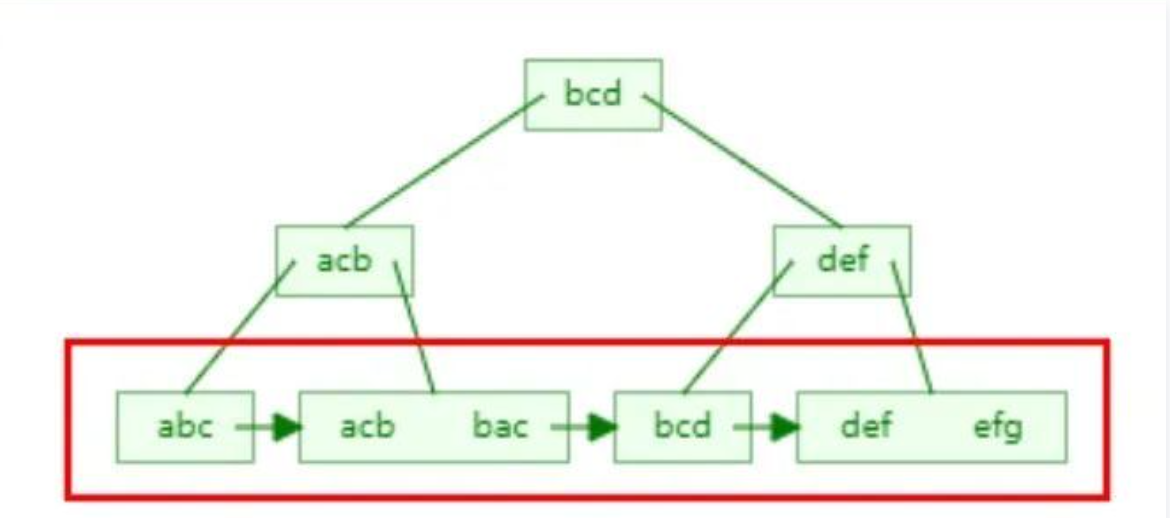
先按照第一个字母排序,如果第一个字母相同,就按照第二个字母排序,以此类推,在左部使用模糊查询时,会出现无序的状态。
例如 : 如果你要查的是所有名字第一个字是“张”的人,你的 SQL 语句的条件是”where name like ‘张 %’”。这时,你也能够用上这个索引,查找到第一个符合条件的记录是 ID3,然后向后遍历,直到不满足条件为止。但是如果是”where name like ‘%三’”,那么就会索引失效。
因此,联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
索引失效
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
- 使用
SELECT *进行查询; - 创建了组合索引,但查询条件未遵守最左匹配原则;
- 在索引列上进行计算、函数、类型转换等操作;
- 以
%开头的LIKE查询比如like '%abc'; - 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
- 发生隐式转换;
当然。实际过程中,可能会出现其他的索引失效场景,这时我们就需要查看执行计划,通过执行计划显示的数据判断查询语句是否使用了索引。
查看执行计划很简单,只需要在sql语句前面添加explain就可以了。
索引下推
这是针对最左前缀原则提出的。
满足最左前缀原则的时候,最左前缀可以用于在索引中定位记录。那些不符合最左前缀的部分,会怎么样呢?
索引下推(Index Condition Pushdown) 是 MySQL 5.6 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。




