(CLUDA)CONTRASTIVE LEARNING FOR UNSUPERVISED DOMAIN ADAPTATION OF TIME SERIES
[Title]CONTRASTIVE LEARNING FOR UNSUPERVISED DOMAIN ADAPTATION OF TIME SERIES
摘要
- **Unsupervised domain adaptation (UDA)**: aims at learning a machine learning model using a labeled source domain that performs well on a similar yet different, unlabeled target domain.
- CLUDA(本文提出): a novel framework for UDA of time series data。 包含以下三个特色
- a contrastive learning framework : learn contextual representations in multivariate time series, so that these preserve label information for the prediction task.
- a custom nearest-neighbor contrastive learning : capture the variation in the contextual representations between source and target domain
- the fifirst framework to learn domain-invariant, contextual representation for UDA of time series data
介绍
Unsupervised domain adaptation (UDA)
Domain adaptation
思想 :给定source dataset(源数据,也就是初始的训练集,有标签),target dataset(目标数据,就是相关域的数据集,无标签),Domain adaptation的目标就是使用提供的所有数据训练一个统计模型,用于预测目标数据的标签。
目的 :在某一个训练集上训练的模型,可以应用到另一个相关但不相同的测试集上。
UDA(无监督领域自适应):
目的 :为了解决传统监督学习需要大量人工标注的问题 。顾名思义,就是将某个领域或者任务学习好的知识或模式,应用到到新的不同但相关?的领域中。
难点 :缓解虚拟源域数据和真实目标域数据分布的差距(每个领域都有自己特有的知识,而这些特有的知识对其它领域反而是一种干扰)。
如现在有两堆数据,一堆是真实的动物照片,一堆是手绘动物的照片。两个数据集的风格是明显不一样的,它们的分布也是明显存在偏差的。如果我们直接在真实的动物照片上训练一个分类器,然后直接用在手绘动物的照片的分类上,性能必然是比较差的。
因此在UDA任务中,我们需要寻找一种“共有特征”。

如在上面的照片中,对于真实的猴子和手绘的猴子,我们需要提炼出猴子的共有特征,如脸庞的形状,毛发的颜色等,摒弃一些领域自己特有的特征,如图片的背景,构图差异等。
思想 : 找到源域与目标与的“共有特征”,专业术语叫“领域不变特征”。
如何找到?比较有代表性的 :最大均值差异(Maximum Mean Discrepancy, MMD)
本文方法:nearest-neighborhood contrastive learning + adversarial learning
应用场景:模拟数据->真实数据;通用数据->特定数据
Contributions
- We propose a novel, contrastive learning framework (CLUDA) for unsupervised domain adaptation of time series. To the best of our knowledge, ours is the fifirst UDA framework that learns a contextual representation of time series to preserve information on labels.
- We capture domain-invariant, contextual representations in CLUDA through a custom approach combining nearest-neighborhood contrastive learning and adversarial learning to align them across domains.
- We demonstrate that our CLUDA achieves state-of-the-art performance. Furthermore, we show the practical value of our framework using large-scale, real-world medical data from intensive care units.
问题定义
- We consider a classifification task for which we aim to perform UDA of time series.
- we have two distributions over the time series from the source domain Ds(labeled) and the target domain Dt(unlabeled).
- Our aim is to build a classififier that generalizes well over target samples T by leveraging the labeled source samples S
框架
ARCHITECTURE
In brief, our architecture is the following.
The feature extractor network F(·) takes the (augmented) time series from both domains and creates corresponding embeddings .
The classififier network C(·) is trained to predict the label of time serie from the source domain using the embeddings .
The discriminator network D(·) is trained to distinguish source embeddings Z* *s from target embeddings Z* *t .
The momentum updated feature extractor *network F˜(·)* and the projector network Q(·) via contrastive learning for each domain : further captures the contextual representation of the time series in the embeddings Z* *s and Z* *t.
Nearest-neighbor CL aligns the contextual representation across domains in the embedding space Z* *s and Z* *t via .
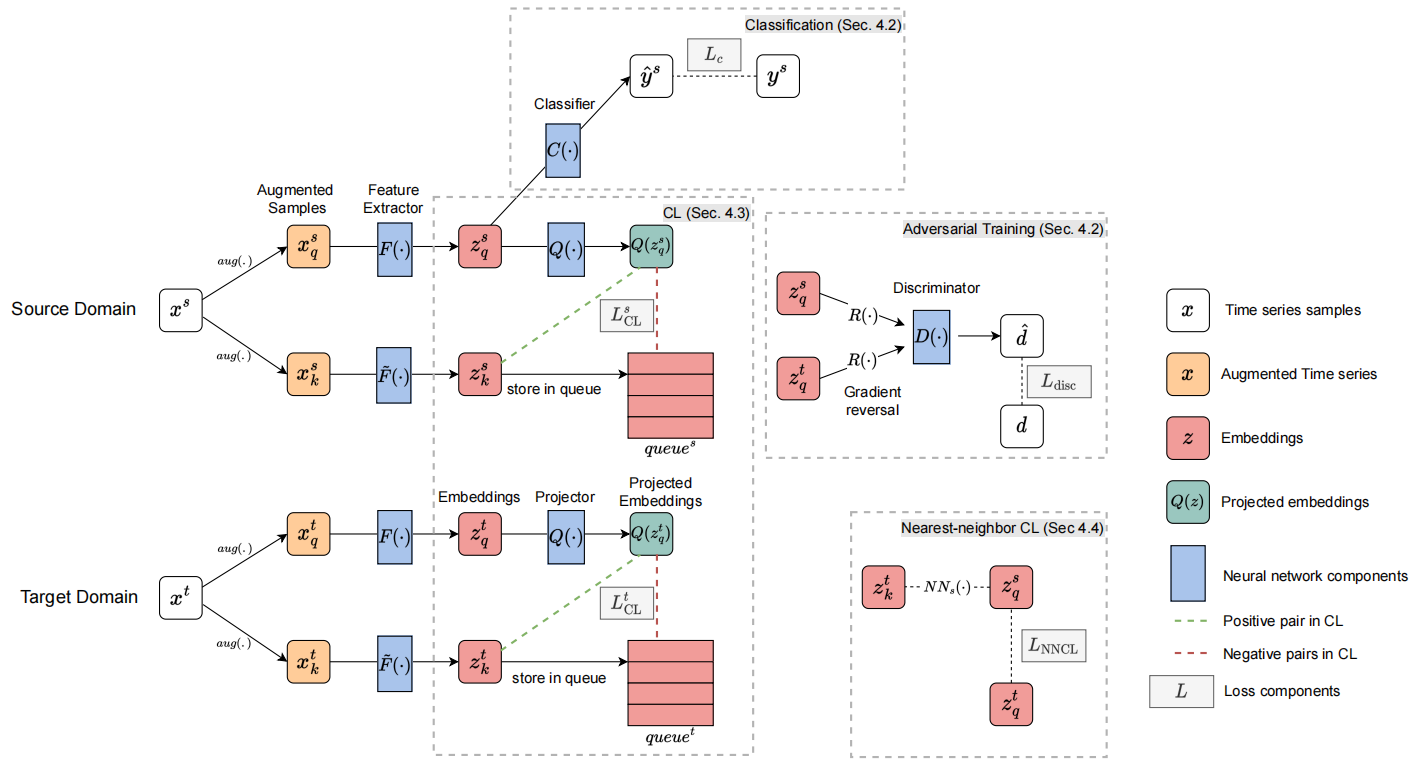
ADVERSARIAL TRAINING FOR UNSUPERVISED DOMAIN ADAPTATION
For the adversarial training, we minimize a combination of two losses
prediction loss Lc : trains the feature extractor F(·) and the classififier C(·).
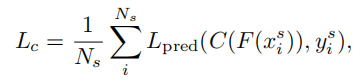
Ns代表目标数,这种方法同时训练了分类器和提取器。
Lpred是交叉熵损失。
domain classifification loss Ldisc : learn domain-invariant feature representations.
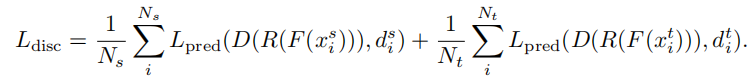
对抗损失,D()可以理解为域判别器(判断样本来自哪个域),F()可以理解为生成器。
D()的目标是最小化域分类损失,F()的目标是同时最大化相同的损失。
R()是梯度反转层(gradient reversal layer)。
以此来学习两个领域之间的“领域不变特征”
GRL作用:将传入到GRL的梯度乘上一个负数,使得在GRL前后的网络的训练目标是相反的。
在接入GRL以后,特征提取器就会有两个目标需要满足
第一是特征提取器需要生成能够预测出正确标签的特征
第二是特征提取器提取的特征需要尽可能无法判断出来自哪个任务域。
这里的主要思想在于:针对无监督领域自适应的对抗性训练
首先在源域中 ,用一个交叉熵损失训练了特征提取器F和分类器C,让 F 和 C 相互配合能够更好的做出分类(本文的目的在于在目标域中做分类)
由于编码器和领域分类器的训练目标是相反的,分别把源域和目标域同一时间的Z作为通过梯度反转层作为对抗生成网络的输入,让F在提取两个域的特征的时候尽量相似,以实现“领域不变特征”的学习。
CAPTURING CONTEXTUAL REPRESENTATIONS
In our CLUDA, we capture a contextual representation of the time series in the embeddings z s and z t ,and then align the contextual representations of the two domains for unsupervised domain adaptation.
With this approach, we improve upon the earlier works in two ways:
- We encourage our feature extractor F(·) to learn label-preserving information captured by the context.
- We hypothesize that discrepancy between the contextual representations of two domains is smaller than discrepancy between their feature space, therefore, the domain alignment task becomes easier.
To capture the contextual representations of time series for each domain, we leverage contrastive learning(MoCo).
momentum-updated feature extractor F~()
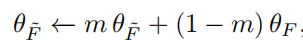
这里使用动量更新提取特征的目的是从每个域捕获上下文表示,至于这样为什么能捕获上下文,见附。
Loss Function
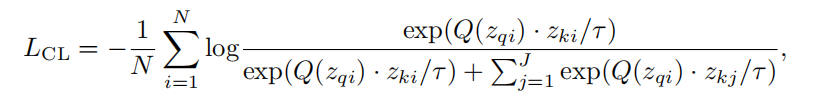
为了捕获上下文表征,采用的方法是动量特征提取+对比学习(基于MoCo)
对比双方 ? (Zq和Zk只是域内样本的不同增强和提取形式。)
查询:Zq在i时刻的嵌入向量
正样本:Zk在i时刻的表征向量
负样本:Zk在j时刻的表征向量
通过对源域和目标域分别进行对比学习,并最小化上面的损失函数,得到的结果就是网络Q()能更精准的将域内的样本(这里是时间)区分开。
ALIGNING THE CONTEXTUAL REPRESENTATION ACROSS DOMAINS
In our CLUDA framework, nearest-neighbor contrastive learning (NNCL) should facilitate the classififier C(·) to make accurate predictions for the target domain.
We achieve this by creating positive pairs between domains, whereby we explicitly align the representations across domains.
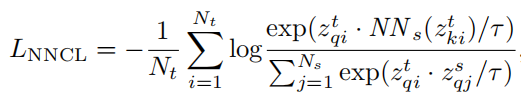
上面的公式 是最近邻对比损失函数。其实和InfoNCE损失函数很像。
InfoNCE loss如下 :
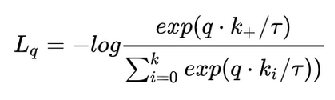
查询主体:目标域的Zq在i时刻的表征向量
正样本:在源域中与查询主题的最近邻向量
负样本:在源域中的其他时刻的相邻
这样分子就是正样本,分母是正样本+负样本。
最近邻的挑选 :要找目标域在i时刻的最近邻,就通过NNs()在源域中的所有时刻中寻找。
TRAINING
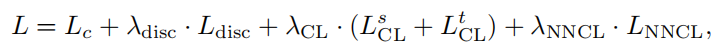
实验
数据集 :MIMIC-IV
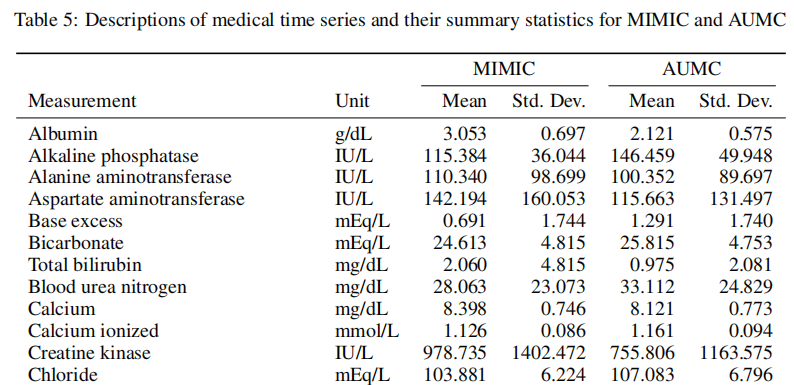
这是来自重症监护病房的公开数据,其目标是预测死亡率。
数据由41个单独的时间序列组成,然后通过无监督的领域适应来预测感兴趣的结果——即失代偿、死亡率和住院时间。
根据患者的年龄组创建4个领域:20-45岁、46-65岁、66-85岁和85+岁。
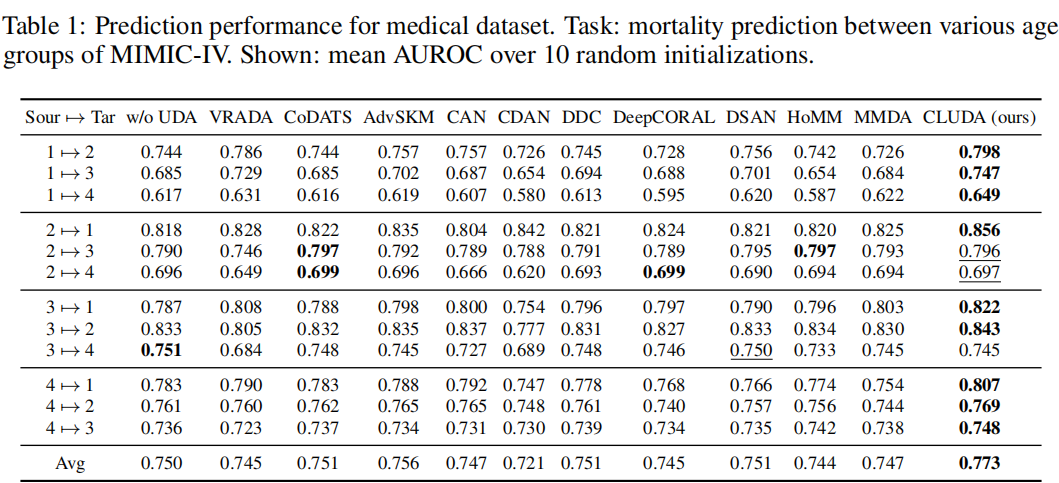
然后,我们对每个跨域场景(即从1 组→组4 到 4 组→组3)应用UDA来预测死亡率。
附:
动量梯度下降
动量梯度下降法是对梯度下降法的改良版本,通常来说优化效果好于梯度下降法。
在深度学习中,Momentum(动量)优化算法是对梯度下降法的一种优化, 它在原理上模拟了物理学中的动量,已成为目前非常流行的深度学习优化算法之一。
目的 : 在梯度下降时,通常会发生摆动(即不是每一步都朝着梯度最小点进发),增加训练时长,如下图 :
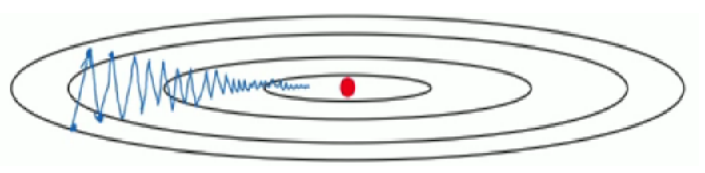
上面图中,红点是梯度最小点,纵向就是摆动。
如何优化? 即让纵向的摆动尽量小,同时保持横向的运动方向比较平稳。
为此,需要知道梯度在过去的一段时间内的大致走向,以消除抖动.这个时候**指数加权平均(exponentially weighted averges)**开始派上用场了
指数加权平均(exponentially weighted averges)也叫指数加权移动平均,通过它可以来计算局部的平均值,来描述数值的变化趋势,有了趋势也就可以用来做预测。
进一步,若要根据平均气温预测明天的温度,显然昨天的温度应该较30天之前的温度权重大一些,因为越早的日期对于预测明天温度所起到的作用越小,这符合我们的常规思维,因此给予每天的温度不同的权重。
下面我们通过温度的局部平均值来描述温度的变化趋势,通过下面的公式来计算平均值
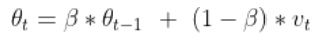
其中,\theta _{t} 代表第 t 天的平均温度值,\beta 代表可调节的参数值。令 \theta _{0} = 0,上式递推式展开如下
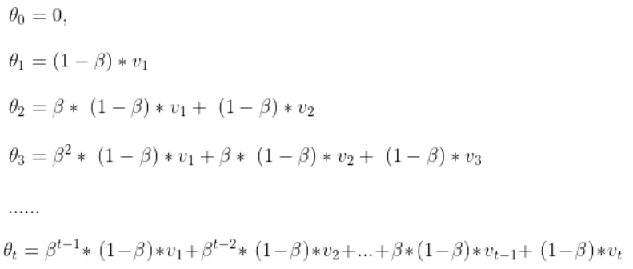
可以看到,随着日期的向后推移,温度的权重以单位β 进行衰减。 当 β 为 0 时,平均气温的计算完全忽略历史信息,随着β 由 0 到 1 不断增大,历史温度的权重衰减速度不断降低,即βs越大,对历史的气温越看重, β越小,时效性越强。
下图绿线是β 为 0.98 时,黄线是β 为 0.02时
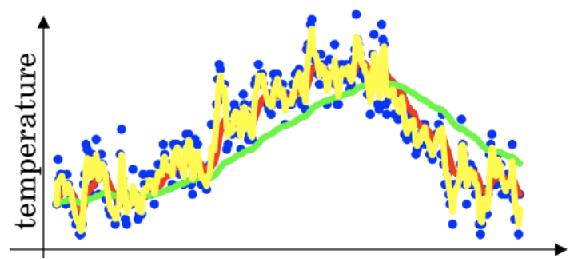
回到动量梯度下降:需要知道梯度在过去的一段时间内的大致走向,以消除抖动.这个时候指数加权平均开始派上用场了
下图是普通梯度下降到动量梯度下降的区别 :
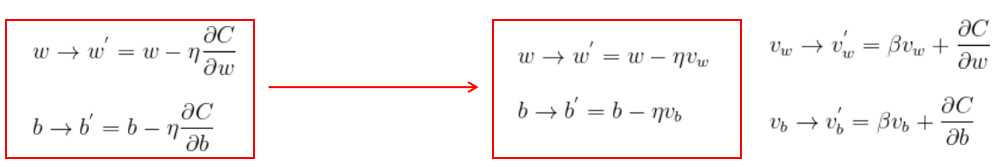
抛弃了直接进行梯度更新,将一段时间内的梯度向量进行了加权平均,分别计算得到梯度更新过程中 w 和 b 的大致走向,一定程度上消除了更新过程中的不确定性因素(如摆动现象),使得梯度更新朝着一个越来越明确的方向前进。也就是说得到了上下文表征.