轨迹预测之实验设置
数据集
对于行人轨迹预测,常用的数据集为ETH [1]和UCY[2] 。这两个数据集是包含了大量的社会交互,这两个数据集中加起来共有1536名行人,上千条真实轨迹,包含行人绕开障碍物、单个行人与人群的相向而行、路口行人转弯等多种真实场景。是行人轨迹预测常用的基准数据集。其中,又分别包含了5个人群数据集。
- EHT : 包含 ETH-univ, ETH-hotel
- UCY : 包含 UCY-zara01, UCY-zara02 and UCY-univ.
这两个数据集以每秒2.5帧的速度标记真实位置,在实验中采用观察过去8帧(3.2秒)来预测未来12帧(4.8秒)的形式进行训练与测试。
[1]S. Pellegrini, A. Ess, K. Schindler, and L. J. Van Gool. You’ll never walk alone: Modeling social behavior for multi-target tracking. In ICCV, volume 9, pages 261–268, 2009.
[2] A. Lerner, Y. Chrysanthou, and D. Lischinski. Crowds by example. In Computer Graphics Forum, volume 26, pages 655–664. Wiley Online Library, 2007.
评价方法
常用的评价方法是 MAD 和 FAD , 出于安全的考虑,还提出了COL(Collision rate)碰撞率 .
MAD : 在最后一个时间步长中,预测输出与真实值之间的欧氏距离。
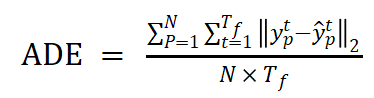
FAD : 所有预测时间步长的地面真实值与预测点之间的平均欧氏距离。
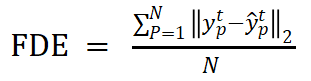
COL : 行人之间的预测轨迹之间发生碰撞的百分比.
参数设置&实施细节
Social-LSTM
We use an embedding dimension of 64 for the spatial coordinates before using them as input to the LSTM. We set the spatial pooling size No to be 32 and use a 8x8 sum pooling window size without overlaps. We used a fifixed hidden state dimension of 128 for all the LSTM models. Additionally, we also use an embedding layer with ReLU (recti-fified Linear Units) non-linearity on top of the pooled hidden state features, before using them for calculating the hidden state tensor Ht i . The hyper-parameters were chosen based on cross-validation on a synthetic dataset. This synthetic was generated using a simulation that implemented the social forces model. This synthetic data contained trajectories for hundreds of scenes with an average crowd density of 30 per frame. We used a learning rate of 0.003 and RMS-prop [14] for training the model. The Social-LSTM model was trained on a single GPU with a Theano [5] implementation.
空间坐标系 : 64维度的嵌入向量 .
LSTM设置 : 均为 128个隐藏状态.
超参数选择 : 基于数据集上的交叉验证,.
训练 : 使用 RMS-pro,学习率为0.003
SR-LSTM
We use single layer MLP to embed the input vectors to32 dimensions, and set the dimension of LSTM hidden state as 64. A sliding time window with a length of 20 and a stride size of 1 is used to get the training samples. All trajectory segments in the same time window are regarded as a mini-batch, as they are processed in parallel. We set the size of mini-batch to 8 during the training stage. We use the single-step mode for training (Fig. 4 (a)), and multi-step mode for validating and testing (Fig. 4 (b)). Adam optimizer is adopted to train models in 300 epochs, with an initial learning rate of 0.001. For training the model with multiple states refifinement layers, we fifixed all basic parameters and only learn the parameters of the additional refifinement layer.
将输入向量通过单层MLP嵌入到32维
LSTM设置 : 均为 64个隐藏状态.
训练集与测试集设置 : 使用一个长度为20、步幅为1的滑动时间窗来获得训练样本。在同一时间窗内的所有轨迹段都被视为一个小批,因为它们是并行处理的(每一小批设置为8个)。
训练 : 使用Adam优化器 ,学习率为0.001
SoPhie
We iteratively trained the generator and discriminator models with the Adam optimizer,using a mini-batch size of 64 and a learning rate of 0.001 for both the generator and the discriminator. Models were trained for 200 epochs. The encoder encodes trajectories using a single layer MLP with an embedding dimension of 16.In the generator this is fed into a LSTM with a hidden dimension of 32; in the discriminator, the same occurs but with a dimension of 64. The decoder of the generator uses a single layer MLP with an embedding dimension of 16 to encoder agent positions and uses a LSTM with a hidden dimension of 32. In the social attention module, attention weights are retrieved by passing the encoder output and decoder context through multiple MLP layers of sizes 64, 128, 64, and 1, with interspersed ReLu activations. The fifinal layer is passed through a Softmax layer. The interactions of the surrounding Nmax = 32 agents are considered; this value was chosen as no scenes in either dataset exceeded this number of total active agents in any given timestep. If there are less than Nmax agents, the dummy value of 0 is used. The physical attention module takes raw VGG features (512 channels), projects those using a convolutional layer, and embeds those using a single MLP to an embedding dimension of 16. The discriminator does not use the attention modules or the decoder network. When training we assume we have observed eight timesteps of an agent and are attempting to predict the next T = 12 timesteps. We weight our loss function by setting λ = 1. Moreover, the generator/discriminator are trained jointly in a traditional GAN setting.
训练 : 使用Adam优化器训练生成器和鉴别器 ,学习率为0.001 .生成器和鉴别器的mini-batch size 均为 64
Social-GAN
We use LSTM as the RNN in our model for both decoder and encoder. The dimensions of the hidden state for encoder is 16 and decoder is 32. We embed the input coordinates as 16 dimensional vectors. We iteratively train the Generator and Discriminator with a batch size of 64 for 200 epochs using Adam [22] with an initial learning rate of 0.001.
编码器 : 隐藏状态为16的LSTM作为RNN
解码器 : 隐藏状态为32的LSTM作为RNN
训练 ; Adam 迭代训练生成器和鉴别器,batch size为 64, 200个epochs,初始学习率为0.001
SHENet
In SHENet, the initial size of group trajectory bank is set to |Z*bank|* = 32. Both the trajectory encoder and the scene encoder have 4 self-attention (SA) layers. The cross-modal transformer is with 6 SA layers and cross-attention (CA) layers. We set all the embed dimensions to 512. For the trajectory encoder, it learns the human motion information with size of T**pas × 512 (T**pas = 8 in ETH/UCY, T**pas = 10 in PAV). For the scene encoder, it outputs the semantic features with size 150 × 56 × 56. We reshape the features from size 150 × 56 × 56 to 150 × 3136, and project them from dimension 150 × 3136 to 150 × 512. We train the model for 100 epochs on 4 NVIDIA Quadro RTX 6000 GPUs and use the Adam optimizer with a fixed learning rate 1e − 5. More details are in the supplementary material.
STAR
Coordinates as input would be fifirst encoded into a vector in size of 32 by a fully connected layer followed with ReLU activation. The dropout ratio at 0.1 is applied when processing the input data. All the transformer layers accept input with feature size at 32. Both spatial transformer and temporal transformer consists of encoding layers with 8 heads. We performed a hyper-parameter search over the learning rate, from 0.0001 to 0.004 with interval 0.0001 on a smaller network and choose the best-performed learning rate (0.0015) to train all the other models. As a result, we train the network using Adam optimizer with a learning rate of 0.0015 and batch size 16 for 300 epochs. Each batch contains around 256 pedestrians in difffferent time windows indicated by an attention mask to accelerate the training and inference process.
输入 : 坐标 ,经过一个全连接层 ,编码为32维的向量 .
dropout ratio率 : 0.1
transformer : 输入为32维的向量, 多头注意力机制的头(时间\空间)均设置为8个
训练 : Adam,学习率为0.0015,batch size为16,共300个epochs。
SGCN
In our experiments, the embedding dimension of self-attention and the dimension of graph embedding are both set to 64. The number of self-attentionlayer is 1. The asymmetric convolution network comprises 7 convolution layers with kernel size S = 3. The spatial temporal GCN and temporal-spatial GCN cascade 1 layer, respectively. And the TCN cascade 4 layers. The thresh old value ξ is empirically set to 0.5. PRelu [13] is adopted as the nonlinear activation δ(·). The proposed method is trained using the Adam [21] optimizer for 150 epochs with data batches of size 128. The initial learning rate is set to 0.001, which is decayed by a factor 0.1 with an interval of 50 epochs. During the inference phase, 20 samples are drawn from the learned bi-variate Gaussian distribution and the closest sample to ground-truth is used to compute the ADE and FDE metrics. Our method is implemented on PyTorch [33]. The code has been published† .
自注意力嵌入维数 和 图嵌入维数 : 64
非对称卷积网络 : 7个核大小为3的卷积层组成
训练 : 初始学习率设置为0.001,在50个epoch的间隔内衰减了0.1倍。
测试 : 从学习到的双变量高斯分布中抽取20个样本,并使用最接近地面真实值的样本来计算ADE和FDE度量
SNCE
In our experiments, we use two different 2-layer MLPs as the projection head ψ(·) and the event encoder ϕ(·). We encode the history observations and future events into 8-dimensional embedding vectors. The distance hyper parameter ρ is set as 0.2 [m] for trajectory forecasting tasks and 0.6 [m] for robot navigation according to the geomet ric size of agents in environments. By default, the sampling horizon δt is set up to 4 and the temperature τ is set as 0.1. All models are trained with the Adam optimizer
距离超参数 : 0.2m
对比学习 : 采样水平δt设置为4,温度τ设置为0.1