
输入url后到看到页面,中间发生了哪些事情?
输入url后到看到页面,中间发生了哪些事情?
大概分为三个步骤
HTTP请求与响应,浏览器渲染,以下分两点讲。。
HTTP请求与响应概览
HTTP请求与响应又主要分为两个步骤:
request请求阶段(客户端向服务端,即浏览器向服务器):
这个步骤牵扯到
- DNS解析
- TCP协议的三次握手与四次挥手
- HTTP与HTTPS的区别
response返回阶段(服务端向客户端,返回页面原代码(html文件,可在控制台source查到):
这个步骤牵扯到
- HTTP状态码
- 304缓存(性能优化)
- HTTP报文
使用 IP 地址访问 Web 服务器为例,谈谈键入网址再按下回车后的HTTP请求与响应。
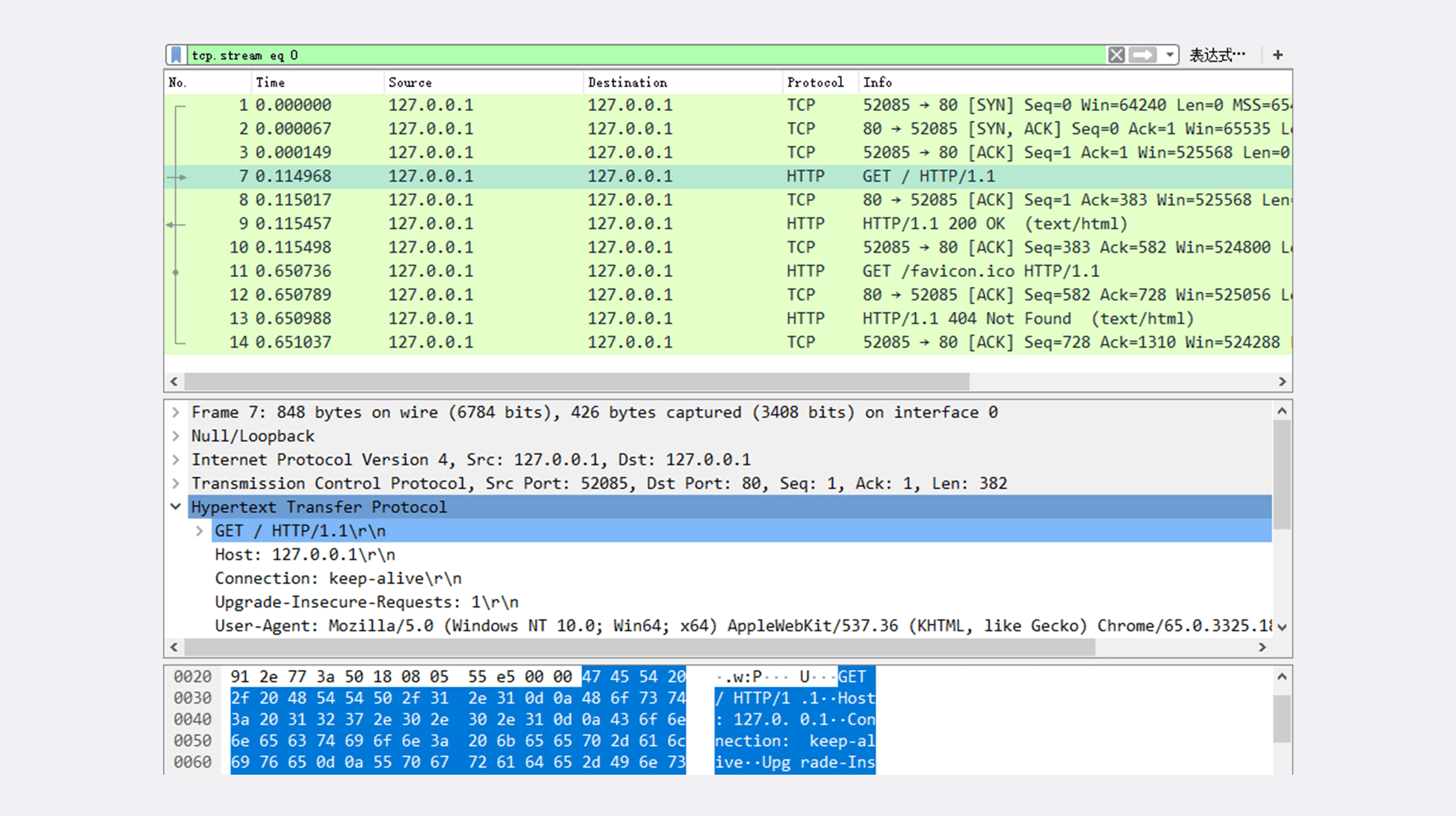
下图是访问本地127.0.0.1地址时,使用wireshark进行抓包,抓取结果的截图。
我们应该知道 HTTP 协议是运行在 TCP/IP 基础上的,依靠 TCP/IP 协议来实现数据的可靠传输。、
所以浏览器要用 HTTP 协议收发数据,首先要做的就是建立 TCP 连接。
如果我们在地址栏里直接输入了 IP 地址“127.0.0.1”,而 Web 服务器的默认端口是 80,所以浏览器就要依照 TCP 协议的规范,使用“三次握手”建立与 Web 服务器的连接。
对应的上面的wireshark抓包截图,就是前三行。52085是浏览器使用的端口, 80是服务器使用的端口。经过 SYN、SYN/ACK、ACK 的三个包之后,浏览器与服务器的 TCP 连接就建立起来了。
有了可靠的 TCP 连接通道后,HTTP 协议就可以开始工作了。于是,浏览器按照 HTTP 协议规定的格式,通过 TCP 发送了一个“GET / HTTP/1.1”请求报文,也就是 Wireshark 里的第四个包。在这个请求行里,“GET”是请求方法,“/”是请求目标,“HTTP/1.1”是版本号,把这三部分连起来,意思就是“服务器你好,我想获取网站根目录下的默认文件,我用的协议版本号是 1.1,请不要用 1.0 或者 2.0 回复我。
随后,Web 服务器回复了第五个包,在 TCP 协议层面确认:“刚才的报文我已经收到了”,不过这个 TCP 包 HTTP 协议是看不见的。ACK只是确认收到,还没处理。
Web 服务器收到报文(是第四个包)后在内部就要处理这个请求。同样也是依据 HTTP 协议的规定,解析报文,看看浏览器发送这个请求想要干什么。它一看,原来是要求获取根目录下的默认文件,好吧,那我就从磁盘上把那个文件全读出来,再拼成符合 HTTP 格式的报文,发回去吧。这就是 Wireshark 里的第六个包“HTTP/1.1 200 OK”,意思就是:“浏览器你好,我已经处理完了你的请求,这个报文使用的协议版本号是 1.1,状态码是 200,一切 OK。”这里就是对请求的响应报文。底层走的还是 TCP 协议。
同样的,浏览器也要给服务器回复一个 TCP 的 ACK 确认,“你的响应报文收到了,多谢”,即第七个包。
这时浏览器就收到了响应数据,但里面是什么呢?所以也要解析报文。一看,服务器给我的是个 HTML 文件,好,那我就调用排版引擎、JavaScript 引擎等等处理一下,然后在浏览器窗口里展现出了欢迎页面。
这之后还有两个来回,共四个包,重复了相同的步骤。这是浏览器自动请求了作为网站图标的“favicon.ico”文件,与我们输入的网址无关。因为没有这个文件,所以服务器在硬盘上找不到,返回了一个“404 Not Found”。至此,“键入网址再按下回车”的全过程就结束了。
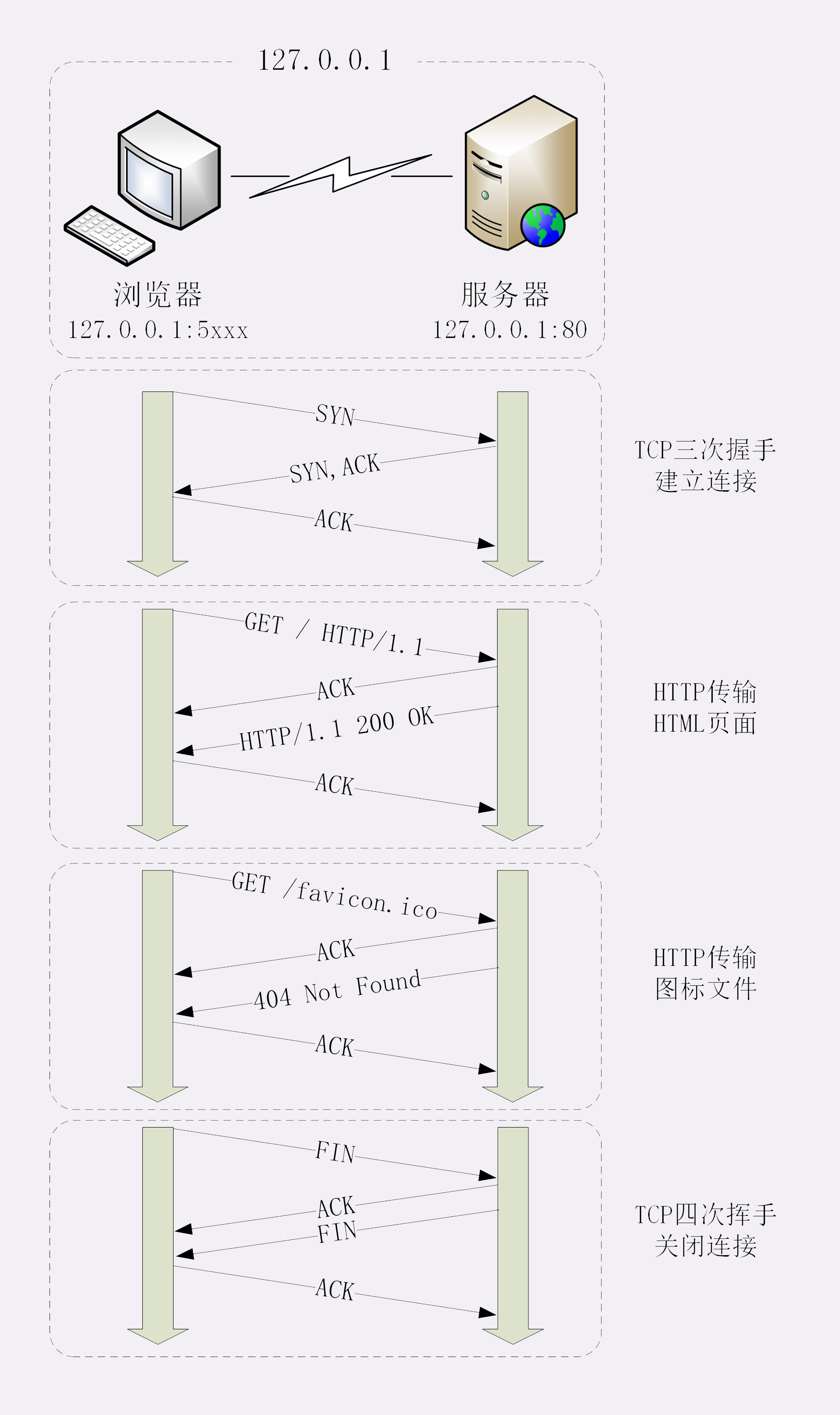
主要过程如下图:注意,上面的wireshark没有四次挥手过程,因为HTTP/1.1是长连接,默认不会立即断掉连接。
总结,总步骤为:
- 浏览器与服务器三次握手建立连接(前三个包)。
- 浏览器向服务器发送请求报文(第四个包)。
- 服务器向浏览器发送确认报文(第五个包)。
- 服务器向浏览器发送响应(第六个包)。
- 浏览器向服务器回复确认(第七个包)。
- 浏览器收到响应数据,进行渲染。
- 最后四个包是浏览器自动请求网站图标的请求,与输入地址无关,返回404
- 注意,上面的截图没有四次挥手过程,因为HTTP/1.1是长连接,默认不会立即断掉连接。
如果是使用域名访问:
浏览器看到了网址里的www,xxx,com,发现它不是数字形式的 IP 地址,那就肯定是域名了,于是就会发起域名解析动作,通过访问一系列的域名解析服务器,试图把这个域名翻译成 TCP/IP 协议里的 IP 地址。
不过因为域名解析的全过程实在是太复杂了,如果每一个域名都要大费周折地去网上查一下,那我们上网肯定会慢得受不了。所以,在域名解析的过程中会有多级的缓存,浏览器首先看一下自己的缓存里有没有,如果没有就向操作系统的缓存要,还没有就检查本机域名解析文件 hosts,如果有一行映射关系,于是浏览器就知道了域名对应的 IP 地址,就可以愉快地建立 TCP 连接发送 HTTP 请求了。
小结:
- HTTP 协议基于底层的 TCP/IP 协议,所以必须要用 IP 地址建立连接;
- 如果不知道 IP 地址,就要用 DNS 协议去解析得到 IP 地址,否则就会连接失败;
- 建立 TCP 连接后会顺序收发数据,请求方和应答方都必须依据 HTTP 规范构建和解析报文;
- 为了减少响应时间,整个过程中的每一个环节都会有缓存,能够实现“短路”操作;
- 虽然现实中的 HTTP 传输过程非常复杂,但理论上仍然可以简化成实验里的“两点”模型。
浏览器渲染
浏览器在内存条开辟栈内存,用于给代码的执行提供环境。这是一个进程。
然后再这个进程中,分配一个主线程,去一行行的解析和执行代码(这也是js是单线程的原因,浏览器只会分配一个线程)。
一行行的代码,进栈执行,执行完出栈。
例如正常html文件第一行通常为:
<!doctype html> //声明文档类型是html会先进栈执行这行,然后出栈。
另外,当遇到link ,script,image,audio等需要额外加载外部资源文件的请求时,都会单独开辟新的线程来加载文件,而主线程继续执行。
浏览器是多线程,但只会分配一个线程来执行js代码,所以js单线程不冲突。
这时,浏览器会开辟task queue空间,把新线程里面的任务加入其中。
步骤2和步骤3粗略的从下面这张图略窥一二。
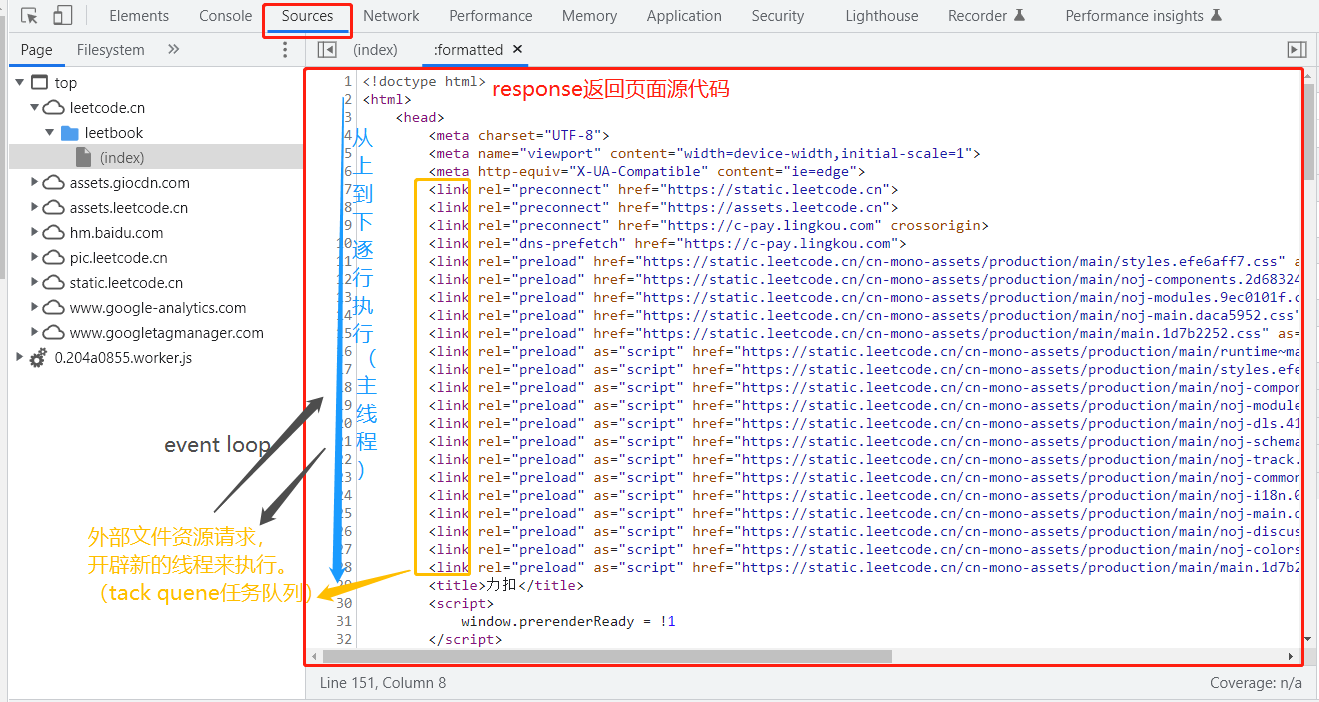
所以浏览器第一次自上而下走完代码后,只解析html生成dom树(css、js等文件未生成),然后来到task queue,看哪个任务完成了,哪个完成就会先执行哪个,这个机制叫做事件循环event loop(主线程-任务队列-主线程-……)。
到此为止页面加载完成。
页面加载过程是,从服务器请求资源并构建DOM树的过程。
为什么要生成DOM树?答:因为浏览器不能直接理解和使用HTML,so,需要将HTML转换为浏览器能够理解的结构,即是DOM树
进入事件循环event loop,解析css,生成CSSOM。浏览器将cssom和dom树结合到一起,形成渲染树render tree。
网页渲染过程指的是通过DOM树渲染出视图内容。
问题:CSS加载会阻塞页面显示吗?
- css加载不会阻塞DOM树的解析
- css加载会阻塞DOM树的渲染
- css加载会阻塞后面js语句的执行
因此,为了避免让用户看到长时间的白屏时间,应该提高css的加载速度。
为了防止css阻塞,引起页面白屏,可以提高页面加载速度
- 使用cdn
- 对css进行压缩
- 合理利用缓存
- 减少http请求,将多个css文件合并
回流layout。根据渲染树,计算他们在设备视口(viewpoint)内的确切大小和位置(处理屏幕大小带来的影响),这个阶段就是回流。每个页面至少需要一次回流,就是在页面第一次加载的时候。
重绘painting。根据渲染树以及回流得到的几何信息,得到节点的绝对像素。
在回流的时候,浏览器会使渲染树中受到影响的部分失效,并重新构造这部分渲染树,完成回流后,浏览器会重新绘制受影响的部分到屏幕中,该过程成为重绘。
display。将像素发送给gpu,展示在页面上。
为什么要了解浏览器渲染页面机制呢?性能优化
了解渲染机制,主要还是为了性能的优化。
前端性能优化第一条:减少HTTP请求次数和大小
- 资源合并压缩
- 图片懒加载
- 音视频走流文件
其他性能优化切入点:DNS缓存、304缓存。。。。



